Базы данных Oracle - статьи
Oracle Data Mining Suite (DARWIN RELEASE 3.7)
Комплект Oracle Data Mining Suite Release 3.7 - это программный продукт data mining, выполняющийся на UNIX-сервере, который предоставляет легкость использования и богатую функциональность для решения сложных проблем. Oracle Data Mining Suite находит скрытые закономерности в данных, строит модели предвидения (predictive models) и помещает свои "предвидения" ("predictions") и "интуиции" ("insights") в базу данных для использования другими приложениями и пользователями Oracle. Иначе говоря, Oracle Data Mining Suite - это "производитель" ("producer") ценной новой информации для других "потребителей" ("consumers") данной организации.
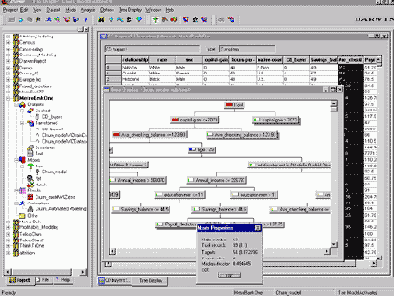
Oracle Data Mining Suite предоставляет легкий в использовании, интуитивно понятный пользовательский интерфейс. Oracle Data Mining Suite предлагает мастер-утилиты (wizards) для упрощения и автоматизации шагов data mining. Например, мастер Key Fields в Oracle Data Mining Suite автоматически находит переменные, которые наиболее нужны (максимально влияют) при решении некоторого конкретного вопроса. Мастер Model Seeker автоматически строит многие модели data mining, показывает интерактивные графы (interactive graphs) и таблицы результатов, а также рекомендует наилучшие модели.
Oracle Data Mining Suite предлагает всю эту функциональность в дружественной пользователю среде, которую бизнес-аналитики могут использовать, причем они могут использовать мощные, возможно, многопроцессорные (SMP) системы и, благодаря этому, смогут "раскапывать" огромные массивы данных и извлекать больше ценной информации.
Oracle Data Mining Suite может получать данные из различных сетевых источников данных. Oracle Data Mining Suite извлекает информацию из баз данных Oracle, используя технологию прямого доступа к данным Oracle (OCI). Корпорация Oracle также предоставляет шлюзы (gateways) к данным, хранимым в других базах данных. Как только вы обеспечите Oracle Data Mining Suite данными, вам часто будет нужно подготовить эти данные для анализа, и Oracle Data Mining Suite предоставляет обширный набор функций преобразования, таких как отбор образцов (sampling), случайный выбор (randomization), генерация новых вычисляемых полей, обработка (handling) отсутствующих значений, слияние (merging), замена значений, расщепление набора данных в последовательность (train) поднаборов, тестирование и наборы данных для сверки (evaluation datasets) и так далее.
На фазе построения моделей Oracle Data Mining Suite предоставляет множество алгоритмов -C&RT, деревья классификации и регрессии (classification and regression trees), также известных как деревья решений, нейронные сети (neural networks), алгоритм нахождения ближайших k соседей (k-nearest-neighbors technique of memory-based reasoning) и кластеризация (clustering). Все эти алгоритмы полнофункциональны (full-featured), протестированы, документированы и хорошо поняты.
Кроме того, они очень мощны, так как все они были реализованы таким образом, чтобы использовать аппаратуру параллельных вычислений для скорости и обработки больших объемов данных - гигабайтов и терабайтов.

Перечислим некоторые основные функции Oracle Data Mining Suite Release 3.7:
- Мастеры прямого импорта и экспорта для доступа к данным из баз данных Oracle и запоминания результатов и предвидений Oracle Data Mining Suite в этих базах данных.
- Мастер Model Seeker, который автоматически строит многие различные модели data mining, представляет результаты в интерактивных графах и таблицах, а также рекомендует лучшие модели.
- Задание вычисляемых полей, которое позволяет пользователям создавать новые выводимые поля, используя более 100 формул - статистических, математических, сравнения и булевской логики.
- Функция показа интерактивного дерева (interactive Tree), которая позволяет пользователям просматривать и запрашивать деревья решений и правила, генерируемые Oracle Data Mining Suite.
- Мастер Key Fields, который автоматически просеивает данные, используя серию погружений по C&RT в данные для определения полей, которые наиболее нужны при решении некоторой конкретной проблемы. Результат мастера Key Fields может быть полезным поднабором полей данных для ввода в OLAP.