Базы данных Oracle - статьи
Как начать работать с Oracle Data Miner
Oracle Data Miner позволяет легко генерировать деревья решений. Чтобы показать это, я сгенерирую дерево решения на рис. 1. Для этого нужно скачать и установить Oracle Data Miner и выполнить следующие шаги по подготовке вашего источника данных для данного примера:
1. Скачать sample data file.
2. Раскрыть (Unzip) содержание (contents), открыть подсказку и перейти (cd) к директории, содержащей скрипт create_user.sql.
3. Подключиться (Log in) к SQL*Plus под именем SYSDBA, и выполнить скрипт create_user.sql.
Этот скрипт создает пользователя SURVEYS с паролем SURVEYS, и предоставляет ему все необходимые полномочия (permissions). Он соединяется с SURVEYS, создает таблицу CUSTOMER_SATISFACTION и вносит в нее 4920 записей. Структура этой таблицы показана в Listing 1.
Code Listing 1: Описание таблицы CUSTOMER_SATISFACTION SQL> desc CUSTOMER_SATISFACTION
CUSTOMER_SATISFACTION_ID NOT NULL NUMBER(10) PRODUCT VARCHAR2(100) VERSION NUMBER(2) LAST_UPGRADE_YEAR VARCHAR2(4) FEEDBACK VARCHAR2(10)
Данные хранятся в этой таблице следующим образом:
Чтобы запустить Oracle Data Miner, найдите bin-директорию, в которую вы распаковали этот скачанный продукт, и дважды нажмите по odminerw.exe. Предоставьте информацию о соединениях в схеме SURVEYS (SURVEYS/SURVEYS), когда появится соответствующая подсказка, и нажмите OK, чтобы сохранить детали соединений. Нажмите OK еще раз, чтобы соединиться и показать интерфейс Oracle Data Miner (см. рис. 2).

Рис. 2: Интерфейс Oracle Data Miner с выбранной таблицей CUSTOMER_SATISFACTION
Отметим, таблица CUSTOMER_SATISFACTION с данными выборки показана справа. Вы можете позднее посмотреть эту таблицу, нажав SURVEYS -> Data Sources -> Tables-> CUSTOMER_SATISFACTION.
Выполните следующие шаги для создания деревьев решений:
- В меню Activity выберите пункт Build.
- Первый экран мастера (wizard) содержит общую информацию. Нажмите Next.
- На шаге 1 из 5: Тип модели (Model Type), оставьте Function Type (тип функции) как Classification (классификация) и Algorithm (алгоритм) как Decision Tree. Нажмите Next. В продукте Oracle Data Miner классификация - это тип функции, или категория алгоритмов, относящихся к классификации, а дерево решений - это алгоритм, который принадлежит данному типу функций.
- На шаге 2 из 5: Данные (Data), удостоверьтесь, что выбранная схема - это SURVEYS и таблица/представление (table/view) - это CUSTOMER_SATISFACTION. Если они еще не выбраны, выберите их из списка. Уникальный идентификатор является в этом случае единственным значением. Удостоверьтесь, что выбран первичный ключ МCUSTOMER_SATISFACTION_ID. В секции Select Columns выберите все столбцы. Нажмите Next.
- На шаге 3 из 5: Использование данных (Data Usage), выберите все колонки, кроме CUSTOMER_SATISFACTION_ID, как ввод и выберите FEEDBACK как назначение. Нажмите Next. Столбец FEEDBACK в таблице содержит ответ как POSITIVE или NEGATIVE. Oracle Data Miner проанализирует этот двоичный ответ применительно ко всем атрибутам, чтобы определить те из них, которые влияют на отзывы клиентов в наибольшей степени.
- На шаге 4 из 5: Для выбора Preferred Target Value, выберите Negative. Нажмите Next. (Это значение может быть изменено в любой момент.) Выбор Negative настраивает Oracle Data Miner на поиск решений, результатом которых является отрицательный ответ, и дерево решений будет структурировано в соответствии с этим. На шаге 5 из 5: Имя действия (Activity Name), измените имя на CUSTOMER_SAT_1 (увеличьте последнее число, если вы повторно выполняете это действие). Нажмите Next.
- В шаге Finish оставьте выбранную опцию Run upon finish и нажмите Finish для начала этого процесса.
На этом этапе Oracle Data Miner определяет лучшие расщепления атрибутов, строит модель и тестирует правила, которые сгенерированы с этим набором данных. Рисунок 3 показывает шаги-действия (activity steps).
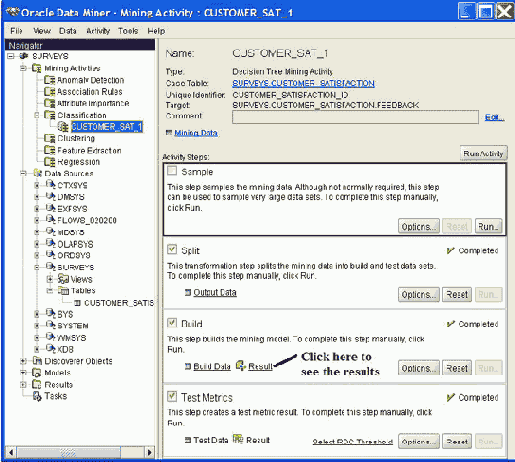
Рис. 3: Шаги- действия классификации CUSTOMER_SAT_1 classification activity steps
Щелкните Result link в Build activity, чтобы увидеть дерево решений, показанное на рис. 4. Отметим, что вы можете контролировать число показываемых уровней узлов. Чтобы увидеть расщепления и ветви, показанные на рис. 1, покажите только два уровня.

Рис. 4: Result Viewer показывает правила расщепления
Результаты на рис. 4 те же самые, что и на рис. 1. Отметим, что первое расщепление или ветвление имеет место на атрибуте Last Upgrade Year (год последней модификации). Если Last Upgrade Year больше или равен 2003, то ответ положителен с 90% уверенности. Отметим, что число значений в данном случае равно 1604 из 2951 в корне. Это примерно 54% от общего числа. Если Last Upgrade Year меньше или равен 2002, ответ предсказывается отрицательным с 91% уверенности. В этом случае в узле 1347 значений, что составляет 46% от общего числа.
Из 4-х узлов 2-го уровня один показывает, что клиенты, использующие версии 2 или 3 продукта A или B, к которым они перешли между 2003 и 2006, с 92% уверенности высказывают положительное мнение о продукте. Другой же узел показывает, что клиенты, использующие продукт A, к которому они перешли между 1999 и 2001, будут, как предсказывается, отрицательно относиться к этому продукту. Безусловно, эта информация будет полезной при планировании поддержки.
Но, очевидно, возможны варианты, когда значение атрибута неопределенно (null) для некоторых записей. Что тогда? Oracle Data Miner определяет не только отношения атрибутов к цели, но и их взаимные отношения. Обратите внимание на секцию Split Rules внизу рис. 4. она показывает замещающее (surrogate) значение для узла ID 1. Если для некоторой записи нет значения Last Upgrade Year, то Oracle Data Miner все-таки включит эту запись в этот узел, если версия 3. Oracle Data Miner определяет это автоматически, не требуя явного задания чего-либо.