Базы данных Oracle - статьи
Почему схема типа "звезда" сжимается лучше нормализованной схемы эталонного теста TPC-H
В двух предыдущих разделах мы рассмотрели коэффициенты сжатия и экономию пространства, которые могут быть получены в реальных схемах: схеме типа "звезда" и нормализованной схеме эталонного теста TPC-H. При сжатии всех таблиц фактов и таблиц итогов коэффициент сжатия для схемы типа "звезда" оказался приблизительно равным 3.1, что позволило сэкономить примерно 67% пространства. То есть, пространство, занимаемое базой данных на диске, сократилось в результате сжатия более чем на половину. С другой стороны, для нормализованной схемы, в которой сжимались две самые большие таблицы, эквивалентные таблицам фактов в хранилище данных, коэффициент сжатия оказался приблизительно равным только 1.4, а экономия пространства - 29%.
Коэффициент сжатия таблиц зависит от избыточности данных в этих таблицах. Данные сжимаются за счет устранения дубликатов значений в каждом блоке базы данных. Более высокая избыточность данных обычно позволяет получить более высокий коэффициент сжатия. Для таблицы, в которой содержится большое количество столбцов с небольшим количеством различающихся значений (на это указывает представление словаря данных DBA_TAB_COL_STATISTICS), автоматически не следует получение высокого коэффициента сжатия. Это скорее зависит от распределения данных и средней длины каждого конкретного столбца. Очевидно, распределение данных определяет количество потенциальных различающихся значений, а средняя длина столбца - количество записей, хранимых в одном блоке.

Рис. 6. Сжатие таблиц схемы типа "звезда" и схемы тестов TPC-H/R
Внимательное рассмотрение количества различающихся значений в двух столбцах (ADDRESS, REGION_ID) таблицы DAILY_SALES схемы типа "звезда" и в двух столбцах (COMMENT, DISCOUNT) таблицы LINEITEM схемы тестов TPC-H/R, объясняет, почему данные нашего примера схемы типа "звезда" сжимаются лучше данных базы данных тестов TPC-H/R. Для каждого столбца на рис. 6 показано общее количество строк в таблице, общее количество различающихся значений, среднее количество строк в блоке (берется из представления словаря данных DBA_TAB_COL_STATISTICS), вычисленное количество различающихся значений в блоке и измеренное среднее количество различающихся значений в блоке (была исследована репрезентативная выборка из блоков). При вычислении количества различающихся значений в блоке мы предполагаем равномерное распределение строк. То есть, вычисленное количество различающихся значений в блоке равно среднему количеству строк в блоке, если общее количество различающихся значений больше количества строк в блоке, в противном случае, оно равно общему количеству различающихся значений. Рассмотрим следующую равномерно распределенную последовательность номеров {1,2,…5}, которая представляет собой строки, состоящие из одного столбца, значением которого является номер:
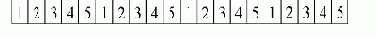
В двух предыдущих разделах мы рассмотрели коэффициенты сжатия и экономию пространства, которые могут быть получены в реальных схемах: схеме типа "звезда" и нормализованной схеме эталонного теста TPC-H. При сжатии всех таблиц фактов и таблиц итогов коэффициент сжатия для схемы типа "звезда" оказался приблизительно равным 3.1, что позволило сэкономить примерно 67% пространства. То есть, пространство, занимаемое базой данных на диске, сократилось в результате сжатия более чем на половину. С другой стороны, для нормализованной схемы, в которой сжимались две самые большие таблицы, эквивалентные таблицам фактов в хранилище данных, коэффициент сжатия оказался приблизительно равным только 1.4, а экономия пространства - 29%.
Коэффициент сжатия таблиц зависит от избыточности данных в этих таблицах. Данные сжимаются за счет устранения дубликатов значений в каждом блоке базы данных. Более высокая избыточность данных обычно позволяет получить более высокий коэффициент сжатия. Для таблицы, в которой содержится большое количество столбцов с небольшим количеством различающихся значений (на это указывает представление словаря данных DBA_TAB_COL_STATISTICS), автоматически не следует получение высокого коэффициента сжатия. Это скорее зависит от распределения данных и средней длины каждого конкретного столбца. Очевидно, распределение данных определяет количество потенциальных различающихся значений, а средняя длина столбца - количество записей, хранимых в одном блоке.
Рис. 6. Сжатие таблиц схемы типа "звезда" и схемы тестов TPC-H/R
Внимательное рассмотрение количества различающихся значений в двух столбцах (ADDRESS, REGION_ID) таблицы DAILY_SALES схемы типа "звезда" и в двух столбцах (COMMENT, DISCOUNT) таблицы LINEITEM схемы тестов TPC-H/R, объясняет, почему данные нашего примера схемы типа "звезда" сжимаются лучше данных базы данных тестов TPC-H/R. Для каждого столбца на рис. 6 показано общее количество строк в таблице, общее количество различающихся значений, среднее количество строк в блоке (берется из представления словаря данных DBA_TAB_COL_STATISTICS), вычисленное количество различающихся значений в блоке и измеренное среднее количество различающихся значений в блоке (была исследована репрезентативная выборка из блоков). При вычислении количества различающихся значений в блоке мы предполагаем равномерное распределение строк. То есть, вычисленное количество различающихся значений в блоке равно среднему количеству строк в блоке, если общее количество различающихся значений больше количества строк в блоке, в противном случае, оно равно общему количеству различающихся значений. Рассмотрим следующую равномерно распределенную последовательность номеров {1,2,…5}, которая представляет собой строки, состоящие из одного столбца, значением которого является номер:
Предположим далее, что среднее количество строк в блоке (Block) равно 4. Тогда отображение строк на блоки будет выглядеть следующим образом:
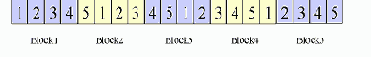
Как видно, в каждом блоке содержится 4 различающихся значения. Впрочем, данная последовательность была выбрана для демонстрации равномерного распределения данных, она не является общим случаем. Читатель может проверить, что разные последовательности могут приводить к уменьшению количества различающихся значений в блоке.
Для столбцов схемы типа "звезда" измеренное среднее количество различающихся значений существенно меньше вычисленного количества различающихся значений. Это указывает на то, что данные являются не равномерно распределенными, а кластеризованными. Это очень распространенное явление для таблиц фактов и таблиц итогов в хранилищах данных; почти в каждой среде хранилища данных при периодическом обновлении данных происходит какое-то группирование или сортировка новых данных. Например, ETL-процесс (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных.), собирающий новую информацию для таблицы фактов из различных источников, должен перед вставкой данных в таблицу фактов сравнивать и агрегировать их, то есть, сортировать данные. Аналогичная кластеризация данных происходит, естественно, и в таблицах итогов, которая выполняется с помощью группирования данных или специализированных OLAP-операций, таких, как операции суперагрегатного группирования rollup и cube.
С другой стороны, в схемах эталонных тестов TPC-H и TPC-R действительное количество различающихся значений в блоке совпадает с вычисленным количеством различающихся значений в блоке, что указывает на строгое равномерное распределение данных. В действительности, генератор данных эталонных тестов TPC-H и TPC-R критиковался за генерацию нормально распределенных данных.
Если данные не кластеризуются, как в случае тестов TPC-H и TPC-R, сортировка данных перед их загрузкой может существенно увеличить сжатие. Выбор столбцов для включения в сортировку зависит от их кардинальности и средней длины. В общем, длинные столбцы обеспечивают большее сжатие по сравнению с короткими столбцами. Что касается кардинальности, то оказалось, что сортировка по столбцам с очень низкой кардинальностью, таким, как GENDER (пол) или MARITAL STATUS (семейное положение), менее эффективна по сравнении с сортировкой по столбцам со средней кардинальностью. Оптимальными столбцами для сортировки представляются те, у которых кардинальность на уровне таблицы равна количеству строк в блоке. Сортировка по столбцам, кардинальность которых меньше количества строк в блоке, менее эффективна, поскольку значения столбца уже имеют большую избыточность. Сортировка по столбцам с каким-либо столбцом с более высокой кардинальностью также приводит к более высокому уровню увеличения сжатия.
Предположим далее, что среднее количество строк в блоке (Block) равно 4. Тогда отображение строк на блоки будет выглядеть следующим образом:
Как видно, в каждом блоке содержится 4 различающихся значения. Впрочем, данная последовательность была выбрана для демонстрации равномерного распределения данных, она не является общим случаем. Читатель может проверить, что разные последовательности могут приводить к уменьшению количества различающихся значений в блоке.
Для столбцов схемы типа "звезда" измеренное среднее количество различающихся значений существенно меньше вычисленного количества различающихся значений. Это указывает на то, что данные являются не равномерно распределенными, а кластеризованными. Это очень распространенное явление для таблиц фактов и таблиц итогов в хранилищах данных; почти в каждой среде хранилища данных при периодическом обновлении данных происходит какое-то группирование или сортировка новых данных. Например, ETL-процесс (Прим. ред. ETL - Extraction, Transmission, Loading - технология извлечения, преобразования и загрузки данных.), собирающий новую информацию для таблицы фактов из различных источников, должен перед вставкой данных в таблицу фактов сравнивать и агрегировать их, то есть, сортировать данные. Аналогичная кластеризация данных происходит, естественно, и в таблицах итогов, которая выполняется с помощью группирования данных или специализированных OLAP-операций, таких, как операции суперагрегатного группирования rollup и cube.
С другой стороны, в схемах эталонных тестов TPC-H и TPC-R действительное количество различающихся значений в блоке совпадает с вычисленным количеством различающихся значений в блоке, что указывает на строгое равномерное распределение данных. В действительности, генератор данных эталонных тестов TPC-H и TPC-R критиковался за генерацию нормально распределенных данных.
Если данные не кластеризуются, как в случае тестов TPC-H и TPC-R, сортировка данных перед их загрузкой может существенно увеличить сжатие. Выбор столбцов для включения в сортировку зависит от их кардинальности и средней длины. В общем, длинные столбцы обеспечивают большее сжатие по сравнению с короткими столбцами. Что касается кардинальности, то оказалось, что сортировка по столбцам с очень низкой кардинальностью, таким, как GENDER (пол) или MARITAL STATUS (семейное положение), менее эффективна по сравнении с сортировкой по столбцам со средней кардинальностью. Оптимальными столбцами для сортировки представляются те, у которых кардинальность на уровне таблицы равна количеству строк в блоке. Сортировка по столбцам, кардинальность которых меньше количества строк в блоке, менее эффективна, поскольку значения столбца уже имеют большую избыточность. Сортировка по столбцам с каким-либо столбцом с более высокой кардинальностью также приводит к более высокому уровню увеличения сжатия.