Базы данных Oracle - статьи
Экономия пространства в результате сжатия
Сжатие таблиц может привести к существенному уменьшению потребности в дисковом пространстве и кеше буферов для таблиц базы данных. Для сжатия данных на уровне блоков алгоритм сжатия использует избыточность данных, поэтому, чем выше избыточность данных в одном блоке, тем больше будут выгоды от сжатия. Хотя может быть и избыточность данных в совокупности блоков, такие данные не могут быть использованы для их дальнейшего сжатия.
Если таблица определена как "сжатая" (compressed), она будет использовать меньше блоков данных на диске, уменьшая, следовательно, потребности в дисковом пространстве. Данные из сжатой таблицы читаются в сжатом формате, и они восстанавливаются только во время доступа к ним. Поскольку данные кешируются в своем сжатом формате, то существенно больше данных может быть размещено в одном и том же объеме кеша буферов (см. рис. 4).
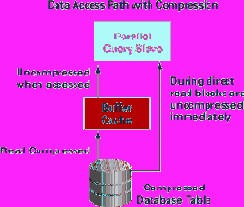
Рис. 4. Пути доступа к сжатым данным
Надписи на рисунке:
· Data Access Path with Compression - пути доступа к сжатым данным;
· Parallel Query Slave - подчиненный процесс параллельного запроса;
· Uncompressed when accessed - восстановление сжатых данных при доступе к ним;
· During direct read blocks are uncompressed immediately - во время прямого чтения блоки восстанавливаются немедленно;
· Buffer Cache - кеш буферов;
· Read compressed - чтение в сжатом формате;
· Compressed Database Table - сжатая таблица базы данных.
Перед измерением экономии пространства в результате сжатия двух наших демонстрационных схем мы определим коэффициент сжатия и экономию пространства. Коэффициент сжатия (КС) таблицы определяется как отношение количества блоков, требуемых для хранения несжатого объекта, к количеству блоков, требуемых для сжатого варианта:
КС = #несжатых_блоков/#сжатых_блоков
Следовательно, экономия пространства (ЭП) определяется следующим образом:
ЭП = ((#несжатых_блоков-#сжатых_блоков)/#несжатых_блоков)х100
Коэффициент сжатия главным образом зависит от содержимого данных на уровне блоков. Неповторяемые поля (поля с высокой кардинальностью), такие, как первичные ключи, не могут быть сжатыми, тогда как поля с очень низкой кардинальностью могут сжиматься очень хорошо. С другой стороны, более длинные поля позволяют получить больший коэффициент сжатия, поскольку экономия пространства будет большей, чем для более коротких полей. Кроме того, если в последовательности столбцов содержится одно и то же содержимое, алгоритм сжатия объединяет эти столбцы в элементе многостолбцового сжатия, что дает еще более лучшие результаты сжатия.
Таблица идентификаторов, в которой содержатся значения полей с множественными экземплярами, автоматически генерируется СУБД Oracle для каждого блока. В большинстве случаев большие размеры блоков позволяют увеличить коэффициент сжатия таблиц базы данных, поскольку с одной таблицей идентификаторов может быть связано большее количество значений столбцов.
Сортировка данных перед их загрузкой может дополнительно увеличить коэффициент сжатия. Чем больше полей с одинаковым содержимым сосредотачивается в каждом блоке, тем более эффективно работает алгоритм сжатия. Если вы знаете, что одно или несколько полей объекта базы данных имеют одинаковые значения - на это указывает небольшое количество уникальных значений сортировка данных по этим полям, вероятно, приведет к увеличению коэффициента сжатия. Тем не менее, сортировка по полям с очень низкой кардинальностью не обязательно приведет к большому увеличению коэффициента сжатия. В результате низкой кардинальности этого поля строки с одинаковыми значениями уже могут иметь высокую концентрацию в каждом блоке. Следовательно, лучшие результаты могут быть достигнуты сортировкой по полям, которые как длинные, так и имеют среднюю кардинальность.