Абсолютная адресация
| Абсолютная адресация
При абсолютной адресации адресное поле команды непосредственно содержит номер целевой ячейки памяти. Таким способом производятся обращения к объектам с постоянными адресами: статическим и внешним переменным, точкам входа подпрограмм. Как и в случае с обсуждавшейся в предыдущем подразделе литеральной адресацией, процессор, который использует такую адресацию, либо должен иметь команды переменной длины, либо его команда должна быть длиннее адреса. Второе условие выполняется не только у процессоров гарвардской архитектуры, но и у многих старых компьютеров с небольшим адресным пространством. Абсолютная адресация в системе команд SPARC У процессоров SPARC реализация абсолютной адресации похожа на реализацию адресации литеральной: под адресацию занимается регистр, командой sethi %hi (addr) , reg в него загружается старшая часть адреса, а затем происходит собственно адресация. Для формирования 64-разрядного адреса необходимо занимать два регистра и выполнять ту же программу, что и в примере 2.1. Обращение к переменной в памяти происходит так, как показано в примере 2.2. Пример 2.2. Обращение к переменной на процессоре SPARC
В модулях, содержащих много обращений к переменным, рекомендуется выделить для этой цели регистр и использовать смещения относительно него — как, кстати, и сделано в приведенном примере. Но это уже совсем не абсолютная адресация. |
Адресация с использованием счетчика команд
| Адресация с использованием счетчика команд
Любой процессор предоставляет как минимум один способ такой адресации: адресация самих команд при их последовательной выборке осуществляется при помощи счетчика команд с постинкрементом. У процессоров с командами переменной длины величина постинкремента зависит от кода команды. Некоторые процессоры позволяют использовать счетчик команд наравне со всеми остальными регистрами общего назначения. Запись в этот регистр приводит к передаче управления по адресу, который соответствует записанному значению. Чтение из этого регистра позволяет узнать адрес текущей команды, что само по себе не очень полезно и часто может быть сделано Другими способами. Однако использование других режимов адресации со счетчиком команд порой позволяет делать неожиданные, но весьма полезные трюки. Литеральная и абсолютная адресация в PDP-11 и VAX VAX и PDP-11 не реализуют в чистом виде ни литерального, ни абсолютного режимов адресации. Вместо этого литерал или адрес помещается в программную память непосредственно за операндом и используется, соответственно, косвенно-регистровый с постинкрементом и косвенный с постинкрементом режимы со счетчиком команд в качестве регистра. При исполнении команды счетчик команд указывает на слово, следующее за текущим отрабатываемым операндом (рис. 2.13). Использование постинкремента приводит к тому, что счетчик увеличивается на размер, соответственно, литерала или адреса, и таким образом, процессор находит следующий операнд. Этот остроумный прием можно рассматривать как своеобразный способ реализовать команды переменной длины.  Рис. 2.13. Реализация литеральной адресации через постинкрементную адресацию счетчиком команд Использование счетчика команд в косвенно-регистровом режиме со смещением позволяет адресовать код и данные относительно адреса текущей команды. Такой режим адресации называется относительным. Программный модуль, в котором используется только такая адресация, позиционно независим: его можно перемещать по памяти, и он даже не заметит факта перемещения, если только не получит управление в процессе самого перемещения, или не будет специально проверять адреса на совпадение. Впрочем, почти такого же эффекта можно достичь базовой адресацией. Многие современные процессоры такого режима адресации для данных не предоставляют, зато почти все делают нечто подобное для адресации кода. А именно, во всех современных процессорах команды условного перехода используют именно такую адресацию: эти команды имеют короткое адресное поле, которое интерпретируется как знаковое смещение относительно текущей команды. Дело в том, что основное применение условного перехода — это реализация условных операторов и циклов, в которых переход осуществляется в пределах одной процедуры, а зачастую всего на несколько команд вперед или назад. Снабжать такие команды длинным адресным полем было бы расточительно и привело бы к ненужному раздуванию кода. Условные переходы на большие расстояния в коде встречаются относительно редко, и чаще всего их предлагают реализовать двумя командами (пример 2.5). Пример 2.5. Реализация условного перехода с длинным смещением Beq distant_label ; Перейти, если равно ; реализуется как Bneq $1 ; Перейти, если не равно Jmp distant_label ; У команд безусловного перехода обычно используется длинное смещение ; или абсолютный адрес $1: Относительные переходы в системе команд SPARC У большинства CISC-процессоров адресное смещение в командах условного перехода ограничено одним байтом. У SPARC такие команды используют адресное поле длиной 22 бита. С учетом того факта, что команды у SPARC всегда выровнены на границу слова (4 байта), такая адресация позволяет непосредственно указать до 4М (4х220=4 194 304) команд или 16 Мбайт, т.е. целиком адресовать сегмент кода большинства реально используемых программ (рис. 2.14).
 Рис. 2.14. Формат команд условного перехода и вызова процессора SPARC Команда вызова подпрограммы у SPARC также использует адресацию относительно счетчика команд, но адресное поле у нее 30-разрядное и интерпретируется как адрес слова, а не байта. При сложении смещения и счетчика команд возможные переполнения игнорируются, поэтому такой командой можно адресовать любое слово (т. е. любую команду) в 32-разрядном адресном пространстве. На первый взгляд, неясно даже, какая польза от того, что адресация производится относительно счетчика команд, а не абсолютно. Но в 64-разрядных процессорах SPARC v9 польза от этого большая — абсолютный 30-разрядный адрес позволял бы адресовать только первое гигаслово памяти, а относительное смещение адресует именно сегмент кода, в какой бы части 64-разрядного адресного пространства он бы ни находился. Программ, имеющих объем более одной гигакоманды, или даже половины гигакоманды, пока что не написано, поэтому 30-разрядного смещения практически достаточно для адресации в пределах любой современной программы. Процессоры, не предоставляющие программисту прямого доступа к счетчику команд, зачастую все-таки дают возможность записывать в него произвольные значения при помощи специальных команд вычислимого перехода и вычислимого вызова. Команды вычислимого вызова широко используются для реализации указателей на функции из таблиц виртуальных методов в объектно-ориентированных языках. Главное применение команд вычислимого перехода -- реализация операторов switch языка C/C++ или case языка Pascal. |
Банки памяти
| Банки памяти
Банки памяти используются, когда адресное пространство процессора мало, а приложение требует. При этом стоимостные и электротехнические ограничения позволяют нам установить в систему гораздо больше памяти, чем процессор может адресовать. Например, у многих" микроконтроллеров адрес имеет длину всего 8 бит, однако 256 байт данных, и тем более 256 команд кода для большинства приложений недостаточно. Многие из ранних персональных компьютеров, основанных на 8-разрядных микропроцессорах i8085 и Z80 с 16-разрядным адресом, имели гораздо больше 64 Кбайт памяти. Например, популярные в годы детства авторов компьютеры Yamaha имели до 2 Мбайт оперативной памяти. Адресация дополнительной памяти в этой ситуации обеспечивается дополнительным адресным регистром, который может быть как конструктивным элементом процессора, так и внешним устройством. Этот регистр дает нам дополнительные биты адреса, которые и обеспечивают адресацию дополнительной памяти. Регистр этот называется расширителем адреса или селектором банка, а область памяти, которую можно адресовать, не изменяя селектор банка, - банком памяти. Значение регистра-селектора называют номером банка. Банковая адресация в 16-разрядных микропроцессорах Внимательный читатель, знакомый с системой команд Intel 8086, не может не отметить, что "сегментные" регистры этого процессора имеют мало общего с собственно сегментацией, описываемой в главе 5. Эти регистры более похожи на причудливый гибрид селектора банков и базового регистра. Как и описываемый далее PIC, I8086 имеет команды "ближних" (внутрибанковых) и "дальних" (межбанковых) переходов, вызовов и возвратов. Относящийся к тому же поколению процессоров Zylog 800 имеет полноценные селекторы банков. Из всех изготовителей 16-разрядных микропроцессоров только инженеры фирмы Motorola осмелились расширить адрес до 24 бит (это потребовало увеличения разрядности регистров и предоставления команд 32-разрядного сложения), все остальные так или иначе экспериментировали с селекторами банков и вариациями на эту тему. Работа с банками памяти данных обычно не представляет больших проблем, за исключением ситуаций, когда нам нужно скопировать из одного банка в другой структуру данных, которую невозможно разместить в регистрах процессора. Существенно более сложную задачу представляет собой передача управления между банками программной памяти. В том случае, когда селектор банка программной памяти интегрирован в процессор, предоставляются специальные команды, позволяющие перезагрузить одновременно "младшую" (собственно регистр PC) и "старшую" (селектор банка) части счетчика команд. Банки команд в Р/С У микроконтроллеров PIC арифметические операции производятся только над младшими 8 битами счетчика команд, поэтому относительные и вычислимые переходы допустимы только в пределах 256-командного банка. Однако полное — с учетом селектора банка — адресное пространство для команд достигает 64 Кбайт, а у старших моделей и 16 Мбайт за счет использования двух регистров-расширителей. Переключение банка осуществляется специальными командами "длинного" — межбанкового — перехода. Если банковая адресация реализована как внешнее устройство, проблема межбанковой передачи управления встает перед нами в полный рост. Поскольку мы не имеем команд межбанкового перехода, любой такой переход состоит минимум из двух команд: переключения банка и собственно перехода. Каждая из них нарушает порядок исполнения команд. Рассмотрим ситуацию детальнее (рис. 2.15): из кода, находящегося в банке 1 по адресу OxlOaf, мы хотим вызвать процедуру, находящуюся в банке 2 по адресу 0x2000. Если мы сначала выполним переключение банка, мы окажемся в банке 2 по адресу ОхЮЬО, не имея никакого представления о том, какой же код или данные размещены по этому адресу. С той же проблемой мы столкнемся, если сначала попытаемся сделать переход по адресу Oxlfff. В качестве решения можно предложить размещение по адресу Oxlfff в банке 1 команды переключения на банк 2. Возможно, для этого придется переместить какой-то код или данные, но мы попадем по желаемому адресу. Впро-Чем, если мы постоянно осуществляем межбанковые переходы, этот подход Потребует вставки команд переключения банка для каждой возможной точки входа во всех остальных банках. Ручное (да и автоматизированное)размещение этих команд — операция чрезвычайно трудоемкая, и возникает естественная идея: сконцентрировать все эти вставленные команды и соответствующие им точки входа в каком-то одном месте. Впрочем, даже эта идея не дает нам ответа на вопрос, как же при такой архитектуре возвращать управление из процедур? Вставлять команду переключения еще и для каждой команды вызова?  Рис. 2.15. Межбанковый переход Развитие этой идеи приводит нас к чему-то, похожему на менеджер оверлеев (см. разд. Оверлеи (перекрытия). программный модуль, который присутствует во всех банках по одному и тому же адресу (рис. 2.16). Если нам нужно вызвать известную процедуру в определенном банке, мы передаем ее адрес и номер банка этому модулю, и он осуществляет сохранение текущего банка, переключение и переход. Если процедура делает возврат, она возвращает управление тому же модулю, который, в свою очередь, восстанавливает исходный банк и возвращает управление в точку вызова. Дальнейшее развитие этой идеи приводит к мысли, что самый простой способ разместить этот код во всех банках — это усложнить схему работы селектора банков, например, всегда отображать первый килобайт адресного пространства на одни и те же физические адреса. Аппаратно это несложно: мы анализируем старшие шесть битов адресной шины процессора. Если они не равны нулю, мы подаем на старшие биты адресной шины памяти содержимое селектора банка, если же равны — нулевые биты. Примерно этим способом и расширяют память большинство микрокомпьютеров на основе 8-разрядных процессоров. Поскольку мы вступили на путь анализа логического адреса, можно пойти и дальше: разбить адресное пространство процессора на несколько банков, каждый со своим селектором.  Рис. 2.16. Переключатель банков Адресное пространство PDP-11 Машины серии PDP-11 имеют 16-разрядный адрес, который позволял адресовать 64 Кбайт. У старших моделей серии это пространство разбито на 8 сегментов по 8 Кбайт каждый. Каждому из этих сегментов соответствует свой селектор банка (в данном случае следует уже говорить о дескрипторе сегмента) (рис. 2.17). Физическое адресное пространство, которое может быть охвачено дескрипторами сегментов, составляет 2 Мбайт, что намного больше адресов, доступных отдельному процессу. На первый взгляд, эта конструкция представляет собой усложненную реализацию банковой адресации, цель которой — только расширить физическое адресное пространство за пределы логического, но тот факт, что, кроме физического адреса, каждый сегмент имеет и другие атрибуты, в том числе права доступа, заставляет нас признать, что это уже совсем другая история, заслуживающая отдельной главы (см. главу 5).
 Рис. 2.17. Виртуальная память PDP-11/20 |
Базово-индексный режим
| Базово-индексный режим
В этом режиме адрес операнда образуется сложением двух или, реже, большего количества регистров и, возможно, еще и адресного смещения. Такой режим может использоваться для адресации массивов — один регистр содержит базовый адрес массива, второй — индекс, откуда и название. Иногда значение индексного регистра умножается на размер операнда, иногда — нет. На первый взгляд, ортогональные архитектуры должны испытывать определенные сложности с-кодированием такой адресации: для этого нужно два регистровых поля, а большинство остальных режимов довольствуются одним регистром. Однако многие ортогональные архитектуры, например VAX, МС680хО, SPARC реализуют этот режим, пусть иногда и с ограничениями. Индексный режим адресации VAX У VAX за операндом, указывающим индексный режим адресации и индексный регистр, следует еще один байт, кодирующий режим адресации и регистр, используемые для вычисления базового адреса (рис. 2.12). Идея разрешить многократное указание индексного регистра в одном операнде, к сожалению, не реализована. Индексный режим адресации в системе команд SPARC SPARC позволяет использовать для вычисления адреса в командах LD, зт и JMPL как сумму двух регистров, так и сумму регистра и 13-разрядного смещения. Таким образом, эти команды реализуют либо косвенно-регистровый режим (если используется смещение и оно равно 0), либо косвенно-регистровый режим со смещением, либо базово-индексный режим без смещения. Это, конечно, беднее, чем у CISC-процессоров, но жить с таким набором вполне можно.  Рис. 2.12. Индексный режим адресации VAX Немало современных процессоров, впрочем, предлагают программисту реализовать такой режим с помощью нескольких команд и с использованием промежуточного регистра, в который следует поместить сумму базового и индексного регистров. |
CISC- и RISC-процессоры
| CISC- и RISC-процессоры
Часто приходится сталкиваться с непониманием термина RISC, общепринятая расшифровка которого — Reduced Instruction Set Computer (компьютер с уменьшенной системой команд). Какой же, говорят, SPARC или PowerPC -RISC, если у него количество кодов команд не уступает или почти не уступает количеству команд в х8б? Почему тогда х86 не RISC, ведь у него команд гораздо меньше и они гораздо проще, чем у VAX 11/780, считающегося классическим примером CISC-архитектуры. Да и технологии повышения производительности у современных х86 и RISC-процессоров используются примерно те же, что и у больших компьютеров 70-х: множественные АЛУ, виртуальные регистры, динамическая перепланировка команд. В действительности, исходно аббревиатура RISC расшифровывалась несколько иначе, а именно как Rational Instruction Set Computer (RISC, компьютер с рациональной системой команд). RISC-процессоры, таким образом противопоставлялись процессорам с необязательно сложной (CISC - Complex Instruction Set Computer, компьютер со сложной системой команд), но "иррациональной", исторически сложившейся архитектурой, в которой, в силу требований бинарной и ассемблерной совместимости с предыдущими поколениями, накоплено множество команд, специализированных регистров и концепций, в общем-то и не нужных, но вдруг отменишь команду двоично-десятичной коррекции, а какое-то распространенное приложение "сломается"? А мы заявляли бинарную совместимость. Скандал! Понятно, что быть "рациональными" в таком понимании могут лишь осваивающие новый рынок разработчики, которых не заботит та самая бинарная совместимость. Уже сейчас, например, фирма Sun, одним из главных достоинств своих предложений на основе процессоров UltraSPARC числит полную бинарную совместимость с более ранними машинами семейства SPARC. Новые процессоры вынуждены поддерживать бинарную совместимость с 64-разрядными младшими родственниками и режим совместимости с 32-разрядными. Где уж тут заботиться о рациональности. С другой стороны, рациональность тоже можно понимать по-разному. В конце 70-х и первой половине 80-х годов общепринятым пониманием "рациональности" считалась своеобразная (с высоты сегодняшнего дня) ориентация на языки высокого уровня. Относительно примитивные трансляторы тех времен кодировали многие операции, например прологи и эпилоги процедур, доступ к элементу массива по индексу, вычислимые переходы (switch в С, Case в Pascal) при помощи стандартных последовательностей команд. Поскольку все меньше и меньше кода писалось вручную и все больше и больше — генерировалось трансляторами, разработчики процессоров решили пойти создателям компиляторов навстречу. Этот шаг навстречу выразился в стремлении заменить там, где это возможно, последовательности операций, часто встречающиеся в откомпилированном коде, одной командой. Среди коммерчески успешных архитектур апофеозом этого подхода следует считать семейство миникомпьютеров VAX фирмы DEC, в котором одной командой реализованы не только пролог Функции и копирование строки символов, но и, скажем, операции удаления и вставки элемента в односвязный список. Приведенная в качестве примера шестиадресной команды команда INDEX — реальная команда этого процессора. Отдельные проявления этой тенденции без труда прослеживаются и в системах команд MC68000 и 8086. Аббревиатура CISC позднее использовалась именно для характеристики процессоров этого поколения. - Другой стороны, неумение трансляторов этого поколения эффективно Размещать переменные и промежуточные значения по регистрам считалось Доводом в пользу того, что от регистров следует отказываться и заменять их Регистровыми стеками или кэш-памятью. (Впрочем, и у VAX, и у MC68000 с Регистрами общего назначения было все в порядке, по 16 штук.) Ко второй половине 80-х развитие технологий трансляции позволило заменить генерацию стандартных последовательностей команд более интеллектуальным и подходящим к конкретному случаю кодом. Разработанные технологии оптимизации выражений и поиска инвариантов цикла позволяли, в частности, избавляться от лишних проверок. Например, если цикл исполняется фиксированное число раз, а счетчик цикла используется в качестве индекса массива, не надо вставлять проверку границ индекса в тело цикла — достаточно убедиться, что ограничитель счетчика не превосходит размера массива. Более того, если счетчик используется только в качестве индекса, можно вообще избавиться и от него, и от индексации, а вместо этого использовать указательную арифметику. Наконец, если верхняя граница счетчика фиксирована и невелика, цикл можно развернуть (пример 2.6). Пример 2.6. Эквивалентные преобразования программы /* Пример возможной стратегии оптимизации. * Код, вставляемый компилятором для проверки границ индекса, * выделен при помощи нестандартного выравнивания. */ int array[100]; int bubblesort(int size) ) int count; do { count=0; for(i=l; i<100; i++) { if (i<0 || i>100) raise(IndexOverflow); if (i-l<0 || i-l>100) raise(IndexOverflow); if (array[i-1]<array[i]) { if (i<0 || i>100) raise(IndexOverflow); int t=array[i]; if (i<0 || i>100) raise(IndexOverflow); if (i-l<0 || i-l>100) raise(IndexOverflow); array[i]=array[i-1]; if (i-l<0 II i-l>100) raise(IndexOverflow); array[i-1]=t; count++; I while (count != 0) ; // оптимизированный внутренний цикл может выглядеть так: register int *ptr=array; register int *limit=ptr; register int t=*ptr++; if (size<100) limit+=size; else limit+=100; while (ptr<limit) { if (t<*ptr) { ptr[-l]=*ptr; *ptr++=t; count++; ) else t=*ptr++; } if (size>100) raise (IndexOverf low) ; По мере распространения в мини- и микрокомпьютерах кэшей команд и данных, а также конвейерного исполнения команд, объединение множества действий в один код операции стало менее выгодным с точки зрения производительности. Это привело к радикальному изменению взглядов на то, каким должен быть идеальный процессор, ориентированный на исполнение откомпилированного кода. Во-первых, компилятору не нужна ни бинарная, ни даже ассемблерная совместимость с чем бы то ни было (отсюда "рациональность"). Во-вторых, ему требуется много взаимозаменяемых регистров — минимум тридцать два, а на самом деле чем больше, тем лучше. В-третьих, сложные комбинированные команды усложняют аппаратуру процессора, а толку от них все равно нет, или мало. Коммерческий успех процессоров, построенных в соответствии с этими взглядами (SPARC, MIPS, PA-RISC) привел к тому, что аббревиатура USC стала употребляться к месту и не к месту — например, уже упоминавшийся Transputer (имевший регистровый стек и реализованный на Уровне системы команд планировщик, т. е. являющийся живым воплощением описанного ранее CISC-подхода) в документации называли RISC-процессором, фирма Intel хвасталась, что ее новый процессор Pentium построен на RISC-ядре (что под этим ни подразумевалось?) и т. д. |
Сетевые протоколы
Сетевые протоколы
Протоколы канального уровня
Протоколы межсетевого уровня
Транспортные протоколы
Прикладные протоколы
Сквозные протоколы и шлюзы
Языки ассемблера
| Языки ассемблера
Непосредственно на машинном языке в наше время не программирует практически никто. Первый уровень, позволяющий абстрагироваться от схемы кодирования команд, — это уже упоминавшийся язык ассемблера. В языке ассемблера каждой команде машинного языка соответствует мнемоническое обозначение. Все приведенные ранее примеры написаны именно на языке ассемблера, да и в тексте использовались не бинарные коды команд, а их мнемоники. Встречаются ассемблеры, которые предоставляют мнемонические обозначения для часто используемых групп команд. Большинство таких языков позволяет пользователю вводить свои собственные мнемонические обозначения — так называемые макроопределения или макросы (macros), в том числе и параметризованные (пример 2.7). Отличие макроопределений от процедур языков высокого уровня в том, что процедура компилируется один раз, и затем ссылки на нее реализуются в виде команд вызова. Макроопределение же реализуется путем подстановки тела макроопределения (с заменой параметров) на место ссылки на него и компиляцией полученного текста. Компиляция ассемблерного текста, таким образом, осуществляется в два или более проходов — на первом осуществляется раскрытие макроопределений, на втором — собственно компиляция, которая, в свою очередь, может состоять из многих проходов, смысл которых мы поймем далее. Часть ассемблера, реализующая первый проход, называется макропроцессором. Пример 2.7. Пример использования макроопределений ; Фрагмент драйвера LCD для микроконтроллера PIC ; (с) 1996, Дмитрий Иртегов. ; Таблица знакогенератора: 5 байт/символ. ; W содержит код символа. Пока символов может быть ; только 50, иначе возникнет переполнение. ; Scanline содержит номер байта (не строки!) ; Сначала определим макрос, а то устанем таблицу сочинять. ; Необходимо упаковать 7 скан-строк по 5 бит в 5 байт. CharDef macro scanl, scan2, scan3, scan4, scanS, зсапб, scan7 ; Следующий символ RetLW (scan? & Oxlc) » 2 RetLW ((scan5 E, 0x10) » 4) + ((зсапб S Oxlf) « 1) + ((scan7 & 0x3) « 6) RetLW ((scan4 & Oxle) » 1) + ((scanb & Oxf) « 4) RetLW ((scan2 & 0x18) » 3) + ((зсапЗ & Oxlf) « 2) + ( (scan4 & Oxl) « 7) RetLW (scanl & Oxlf) + ( (scan2 & 0x7) « 5) endm FetchOneScanline IFNDEF NoDisplay ClrF PCLATH AddWF PCL, 1 NOP ; else RetLW 0 endif ; А вот идет собственно таблица: Nolist ; О CharDef В'OHIO',В110001',В'10001',В'10001',В'10001',В'10001',В'01110' ; 1 CharDef В'00100',В'01100',В'00100',В'00100',В100100',В'00100',В'01110' ; 2 CharDef В'OHIO',В'10001',В'00001',В'00010',В100100',В'01000',В'11111' ; 3 CharDef В'01110',В'10001',В'00001',В'00110',В100001',В110001',В'OHIO' ; 4 CharDef В'00010',В'00110',В'01010',В'10010',В'11111',В'00010', В'00010' ; 5 CharDef В'11111',В'10000',В'11110',В'00001',В'00001',В110001',В1OHIO' ; б CharDef В'OHIO1,840001' ,В' 10000',В' НПО' ,В' 10001' ,В'10001' ,В'OHIO1 ; 7 CharDef В'11111',В'00001',В'00010',В'00100',В'01000',В'01000',В'01000' ; 8 CharDef В'OHIO', В'10001' ,В'10001' ,В'OHIO' , В'10001', В'10001' ,В'OHIO' ; 9 CharDef В'OHIO', В'10001', В'10001' ,В'01111' ,В'00001' ,В'10001' ,В'OHIO' 4 Зэк Х(, Constant CharacterA = Oxa CharDef В ' 00100 ', В ' 01010 ', В ' 10001', В110001' ,841111' , В' 10001' ,В' 10001' Ifndef NO_ALPHABET ; В Constant CharacterW = Oxb CharDef В'11110',В'10001',B'10001',В'11110' ,В'10001' ,В'10001' ,В'11110' else ; Р — для аона CharDef В' 11110 ',840001', В '10001', В '10001', В' 11110 ',840000', В '10000' endif ; С CharDef В'01110',В'10001',В'10000',ВЧОООО',В'10000',В110001',В'01110' ; о CharDef В' 11110 ',В' 10001 ',В' 10001 ',В' 10001 ',840001', В' 10001 ',841110' ; Е CharDef B'lllll' ,ВЧ0001', В'10000', В'11110 ' ,В'10000', В'10001' ,В'11111' ; F CharDef В'11111',В'10001',В'10000',В'11110',В'10ЮОО',В'10000',В'10000' ; пробел Constant SPACE_CHARACTER = 0x10 CharDef В'00000',В'ООООО',В'ООООО',В'00000',В'00000',В100000',В'00000' Constant DASH_CHARACTER = Oxll CharDef В'00000',В'00000',В'00000',В'11111',В'00000',В'ООООО',В'ООООО' List Макропроцессор, кроме раскрытия макросов, обычно предоставляет также директивы условной компиляции — в зависимости от условий, те или иные участки кода могут передаваться компилятору или нет. Условия, конечно же, должны быть известны уже на этапе компиляции. Например, в зависимости от типа целевого процессора одна и та же конструкция может реализоваться как в одну команду, так и эмулирующей программой. В зависимости от используемой операционной системы могут применяться разные системные вызовы (это чаще случается при программировании на языках высокого уровня), или в зависимости от значений параметров макроопределения, макрос может порождать совсем разный код. Макросредства есть не только в ассемблерах, но и во многих языках высокого уровня (ЯВУ). Наиболее известен препроцессор языка С. В действительности, многие средства, предоставляемые языками, претендующими на большую, чем у С, "высокоуровневость" (что бы под этим ни подразумевалось), также реализуются по принципу макрообработки, т. е. при помощи текстовых подстановок и компиляции результата: шаблоны (template) C++, параметризованные типы Ada и т. д. Умелое использование макропроцессора облегчает чтение кода и увеличивает возможности его повторного использования в различных ситуациях. Злоупотребление же макросредствами (как, впрочем, и многими другими мощными и выразительными языковыми конструкциями) или просто бестолковое их применение может приводить к совершенно непонятному коду и трудно диагностируемым ошибкам, поэтому многие теоретики программирования выступали за полный отказ от использования макропроцессоров. Современные методы оптимизации в языках высокого уровня — проверка константных условий, разворачивание циклов, inlme-функции — часто стирают различия между макрообработкой и собственно компиляцией. Кроме избавления программиста от необходимости запоминать коды команд, ассемблер выполняет еще одну, пожалуй, даже более важную функцию: он позволяет снабжать символическими именами (метками) или (символами) команды или ячейки памяти, предназначенные для данных. Значение этой возможности для практического программирования трудно переоценить. Рассмотрим простой пример из жизни: мы написали программу, которая содержит команду перехода (бывают и программы, которые ни одной команды перехода не содержат, но это вырожденный случай). Затем, в процессе тестирования этой программы или уточнения спецификаций мы поняли, что между командой перехода и точкой, в которую переход совершается, необходимо вставить еще два десятка команд. Для вставки необходимо пересчитать адрес перехода. На практике, вставка даже одной только инструкции часто затрагивает и приводит к необходимости пересчитывать адреса множества команд перехода, поэтому возможность автоматизировать этот процесс крайне важна. Важное применение меток — организация ссылок между модулями в программах, собираемых из нескольких раздельно компилируемых файлов. Изменение объема кода или данных в любом из модулей приводит к необходимости пересчета адресов во всех остальных модулях. В современных программах, собираемых из сотен отдельных файлов и содержащих тысячи индивидуально адресуемых объектов, выполнять такой пересчет вручную невозможно. Способы автоматического решения этой задачи обсуждаются в разд. Сборка программ. Фаза сопоставления символов с реальными адресами присутствует и при компиляции языков высокого уровня — компилятор генерирует символы не только для переменных, процедур и меток, которые могут быть использованы в операторе goto, но и для реализации "структурных" условных операторов и циклов. Нередко в описании компилятора эту фазу так и называют — ассемблирование. Многие компиляторы как старые, так и современные, например, популярный компилятор GNU С, даже не выполняют фазу ассемблирования самостоятельно, а вместо этого генерируют текст на языке ассемблера и вызывают внешний ассемблер. Средства межпроцессного взаимодействия современных ОС позволяют передавать этот промежуточный текст, не создавая промежуточного файла, поэтому для конечного пользователя эта деталь реализации часто оказывается незаметной. Компиляторы, имеющие встроенный ассемблер, такие, как Microsoft C/C++ или Watcom, часто могут генерировать ассемблерное представление порождаемого кода. Это бывает полезно при отладке или написании подпрограмм на ассемблере, которые должны взаимодействовать с откомпилированным кодом. |
Косвенно-регистровый режим
| Косвенно-регистровый режим
В этом режиме, как и в регистровом, адресное поле не используется. Значение регистра интерпретируется как адрес операнда. Данный режим используется для разыменования указателей или для обращения к памяти по предварительно вычисленному адресу. Некоторые процессоры, такие, как PDP-11, VAX, МСбЗОхО, имеют любопытные варианты этого режима — адресацию с постинкрементом и предек-рементом. Постинкремент означает, что после собственно адресации значение регистра увеличивается на величину адресуемого объекта. Предекремент, соответственно, означает, что регистр уменьшается на ту же величину перед адресацией. Эти режимы могут использоваться для разнообразных целей, например для реализации операций над текстовыми строками или поэлементного сканирования массивов. Но одно из основных назначений -- это реализация стека. Стек Стек, или магазин — это структура данных, над которой мы можем осуществлять две операции: проталкивание (push) значения и выталкивание (pop). Значения выталкиваются из стека в порядке, обратном тому, в котором проталкивались: LIFO (Last In, First Out, первый вошел, последний вышел). Стековые структуры находят широкое применение при синтаксическом разборе арифметических выражений и алголоподобных языков программирования [Кормен/Лейзерсон/Ривест 2000]. Самая простая реализация стека — это массив и индекс последнего находящегося в стеке элемента (рис. 2.7). Этот индекс называется указателем стека (SP - Stack Pointer). Стек может расти как вверх, так и вниз [(рис. 2.8). Широко применяются также реализации стеков в виде односвяз-|ных списков.  Рис. 2.7. Стек на основе массива  Рис. 2.8. Стеки, растущие вверх и вниз При реализации стека скалярных значений удобно использовать непрерывную область памяти в качестве массива, регистр SP в качестве указателя и режимы адресации с постинкрементом и предекрементом при реализации команд проталкивания и выталкивания. Действительно, команда MOVE x, -(SP) приведет к тому, что указатель стека уменьшится на размер х, и мы положим х в освободившуюся память. Напротив, команда MOVE (SP)+, у приведет к получению значения и продвижению указателя стека в обратном направлении. Поэтому первая команда имеет также мнемоническое обозначение PUSH х а вторая POP у Если мы поместим несколько значений в стек командой PUSH, команда POP вытолкнет их из стека в обратном порядке. Стек можно использовать для хранения промежуточных данных (см. пример 2.3) и при реализации арифметических выражений — например, команда ADD (SP)+, (SP) в точности воспроизводит описанную выше семантику безадресной команды ADD стековой архитектуры. Впрочем, безадресной команде ADD операнды не нужны, а в данном случае они просто не используются, но никуда не исчезают. Команда получается длиннее: у типичной стековой архитектуры команда сложения занимает 1 байт, у PDP-11 ее имитация занимает 2 байта, а у VAX — целых три. Поэтому, если мы хотим использовать стековую технику генерации кода, лучше использовать предназначенный для этого процессор. Пример 2.3. Использование стека для хранения промежуточных значений void swap(int &a, int &b) { int t; t=a; a=b; b=t; } ;Для простоты мы не рассматриваем механизм передачи параметров ; и считаем, что они передаются в регистрах А и В .GLOBL swap swap: POSH (A) MOVE (B) , (A) POP (B) RET. Одно из основных назначений стека в регистровых архитектурах — это сохранение адреса возврата подпрограмм. Кроме того, если принятое в системе соглашение о вызовах подпрограмм предполагает, что вызываемая процедура должна сохранить все или некоторые регистры, которые использует сама, стек обычно применяют и для этого. Неортогональные процессоры, такие, как х86, часто предоставляют специальные команды PUSH и POP, работающие с выделенным регистром SP (Stack Pointer), который не может быть использован для других целей. |
Косвенно-регистровый режим со смещением
Адрес операнда образуется путем сложения регистра и адресного поля команды. Этот режим наиболее богат возможностями и, в зависимости от стиля использования, имеет много других названий, например базовая адресация или индексная адресация. Адресное поле необязательно содержит полноценный адрес и может быть укороченным.
Команды id/st процессора SPARC, используемые в примере 2.2, реализуют косвенно-регистровую адресацию с 13-разрядным смещением.
Возможные варианты использования этого режима адресации многочисленны. Например, если смещение представляет собой абсолютный адрес начала массива, а в регистре хранится индекс, этот режим может использоваться для индексации массива. В этом случае смещение должно представлять собой полноценный адрес.
3 другом случае, в регистре может храниться указатель на структуру Данных, а смещение может означать смещение конкретного поля относительно начала структуры. Еще один вариант -- регистр хранит указатель на стековый кадр или блок параметров процедуры, а смещение -адрес локальной переменной в этом кадре или определенного параметра.
В этих случаях можно использовать (и обычно используется) укороченное смещение.
Стековый кадр
Стековый кадр является стандартным способом выделения памяти под локальные переменные в алголоподобных процедурных языках (С, C++, Pascal) и других языках, допускающих рекурсивные вызовы.
Семантика рекурсивного вызова в алголоподобных языках требует, чтобы каждая из рекурсивно вызванных процедур имела собственную копию локальных переменных. В SPARC это достигается сдвигом регистрового окна по регистровому файлу (рис. 2.9), но большинство других процессоров такой роскоши лишены и вынуждены выделять память под локальные переменные в стеке, размещаемом в ОЗУ.

Рис. 2.9. Регистровый стек процессора SPARC
Для этого вызванная процедура уменьшает (если стек растет вниз) указатель стека на количество байтов, достаточное, чтобы разместить переменные. Адресация этих переменных у некоторых процессоров (например, у PDP-11) происходит относительно указателя стека, а у большинства — например, у МС680хО и VAX, с большим количеством регистров или у х86, указатель стека которого нельзя использовать для адресации со смещением — для этой цели выделяется отдельный регистр (рис. 2.10, пример 2.4).
Пример 2.4. Формирование, использование и уничтожение стекового кадра. Код на языке С и результат его обработки GNU С 2.7.2.1 (комментарии автора)
#include <stdio.h>
# include <strings.h>
/* Фрагмент примитивной реализации сервера SMTP (RFC822) */
int parse_line(FILE * socket)
{
/* Согласно RFC822, команда имеет длину не более 4 байт,а вся строка — не более 255 байт V char cmd[5], args [255]; fscanf (socket, "%s %s\n", cmd, args);
if (stricmpfcmd, "HELO")==0) {
fprintf (socket, "200 Hello, %s, glad to meet you\n", args);
return 200;
)
/* etc */
fprintf (socket, "500 Unknown command %s\n", cmd);
return 500;
.file "sample" gcc2_compiled. : _ gnu_compiled_c : .text LCO:
.ascii "%s %s\12\0" LCI:
.ascii "HELCAO" LC2:
.ascii "200 Hello, %s, glad to meet you\12\0" LC3:
.ascii "500 Unknown command %s\12\0"
.align 2, 0x90 .globl _parse_line _parse_line:
; x86 имеет для этой цели специальную команду enter, но она может ; формировать кадры размером не более 255 байт. В данном случае кадр ; имеет больший размер, и его необходимо формировать вручную.
pushl %ebp ; Сохраняем указатель кадра
; вызвавшей нас подпрограммы.
movl %esp, %ebp ; Формируем указатель нашего кадра
subl $264,%esp ; И сам кадр. ; Конец пролога функции
leal -264 (%ebp) , %еах ; Помещаем в стек указатель на args • pushl %eax
leal -8 (%ebp) , %еах ; ... на cmd
pushl %eax
pushl $LCO ; на строковую константу
; Наши собственные параметры тоже адресуются относительно кадра. movl 8(%ebp),%eax ; Параметр socket мы тоже проталкиваем pushl %eax ; в стек
call fscanf ; Вызов (параметры в стеке) addl $16,%esp ; очищаем стек
; в языке С переменное количество параметров, поэтому вычищать их из
; стека должна вызывающая процедура. Вызываемая просто не знает,
; СКОЛЬКО ИХ бЫЛО.
pushl $LC1
leal -8(%ebp),%eax
pushl %eax
call _stricmp
addl $8,%esp
movl %eax,%eax ; выключенная оптимизация в действии :)
; А ведь недалеки времена, когда компиляторы только такое и умели ; генерировать.
testl %eax,%еах
jne L14
leal -264(%ebp),%еах
pushl %eax
pushl $LC2
movl 8(%ebp),%eax
pushl %eax
call _fprintf
addl $12,%esp
; Обратите внимание, что компилятор не стал генерировать второй эпилог ; функции на втором операторе return.
movl $200,%eax
jmp L13
» Выравнивание потенциальных точек перехода на границу слова полезно: » процессор не будет тратить дополнительный цикл шины на чтение » невыровненной команды. Для выравнивания используется команда NOP ; (код операции 0x90).
align 2,0x90 L14:
leal -8(%ebp),%еах
Pushl %eax
Pushl $LC3
movl 8(%ebp),%eax pushl %eax
call _fprintf
addl ?12,%esp
movl $500,%eax
jmp L13
.align 2,0x90 L13:
; Команда leave совершает действия, обратные прологу функции: ; Она эквивалентна командам: move %ebp, %esp; pop %ebp. ; Размер кадра явным образом не указывается, поэтому ограничений ; на этот размер в данном случае нет.
leave
ret

Рис. 2.10. Стековый кадр
Примечание
Обратите внимание, что программа из примера 2.4 содержит серьезнейшую ошибку. В комментариях сказано, что команда обязана иметь длину не более 4 байт, а вся строка вместе с аргументами не более 255. Если программа-клиент на другом конце сокета (сетевого соединения) соответствует RFC822 [RFC822], так оно и будет. Но если программа требованиям этого документа не соответствует, нас ждет беда: нам могут предложить более длинную команду и/или более длинную строку. Последствия, к которым это может привести, будут более подробно разбираться в главе 12.
Но вернемся к стековым кадрам.
Стековые кадры в системе команд SPARC
Микропроцессоры SPARC также не могут обойтись без стекового кадра. Во-первых, не всегда локальные переменные процедуры помещаются в восьми 32-разрядных локальных регистрах. Именно такая процедура приведена в примере 2.4. Во-вторых, нередки ситуации, когда в качестве параметров надо передать по значению структуры, для которых 6 регистров-параметров тоже не хватит. В-третьих, глубина регистрового файла ограничена и при работе рекурсивных или просто глубоко вложенных процедур может исчерпаться. В-четвертых, в многозадачной системе регистровый файл может одновременно использоваться несколькими задачами. Все эти проблемы решаются при помощи создания стекового кадра [www.sparc.com v9].
Для этой цели используются регистры Isp (о6) и %fp (i6). Команда save %sp, -96 %sp делает следующее: она складывает первые два операнда, сдвигает стековый кадр и помещает результат сложения в третий операнд. Благодаря такому порядку исполнения отдельных операций, старый %sp становится %fp, а результат сложения помещается уже в новый %sp.
Самую важную роль стековые кадры играют при обработке переполнений регистрового файла. Регистровый файл SPARC представляет собой кольцевой буфер, доступность отдельных участков которого описывается привилегированными регистрами CANSAVE и CANRESTORE. Окна, находящиеся между значениями этих двух регистров, доступны текущей программе (рис. 2.11). На рисунке показано состояние регистрового файла, в котором текущий процесс может восстановить один стековый кадр (CANRESTORE=1) и сохранить три (CANSAVE=3). Регистр OTHERWIN указывает количество регистровых окон, занятых другим процессом. Регистровое окно w4 на рисунке (обозначенное как перекрытие) занято лишь частично. Текущее окно, частично занятое окно и участки регистрового файла, описанные перечисленными регистрами, в сумме должны составлять весь регистровый файл, так чтобы соблюдалось отношение CANSAVE + CANRESTORE + OTHERWIN = NWINDOWS - 2, Где NWINDOWS- количество окон (на рисунке регистровый файл имеет 8 окон, т. е. 128 регистров).

Рис. 2.11. Регистровый файл SPARC в виде кольцевого буфера. Регистры CANSAVE и CANRESTORE (цит. по [www.sparc.com v9])
Когда же программа пытается сдвинуть свое окно за описанные границы (в ситуации, изображенной на рис 2.11 это может произойти после вызовов четырех вложенных процедур или после возврата из двух процедур — текущей и соответствующей окну w7), генерируются исключительные состояния заполнения окна (window fill) и сброса окна (window spill). При этом вызывается системная процедура, которая освобождает окна из интервала OTHERWIN, сбрасывая их содержимое в стековые кадры соответствующих процедур и при заполнении восстанавливает содержимое принадлежащего нам окна из соответствующего кадра.
В многозадачной системе заполнение и сброс окна может произойти в любой момент, поэтому пользовательская программа всегда должна иметь по стековому кадру на каждое из используемых ею регистровых окон, а указатель на этот кадр должен всегда лежать в %sp соответствующего окна. При этом очень важно, чтобы создание стекового кадра и сдвиг регистрового окна производились одной командой.
Многопроходное ассемблирование
| Многопроходное ассемблирование
При ассемблировании с использованием меток возникает специфическая проблема: команды могут ссылаться на метки, определенные как до, так и после них по тексту программы. Следовательно, операндом команды может оказаться метка, которая еще не определена. Адрес, соответствующий этой метке, еще неизвестен, поэтому мы должны будем, так или иначе, вернуться к ссылающейся на нее команде и записать адрес. Эта же проблема возникает и при компиляции ЯВУ: предварительное определение переменных и процедур указывает тип переменной и количество и типы параметров процедуры, но не их размещение в памяти, а именно оно нас и интересует при генерации кода. Две техники решения этой проблемы называются одно- и двухпроходным ассемблированием [Баррон 1974]. При двухпроходном ассемблировании, на первом проходе мы определяем адреса всех описанных в программе символов и сохраняем их в промежуточной таблице. На втором проходе мы осуществляем собственно ассемблирование — генерацию кода и расстановку адресов. Если адресное поле имеет переменную длину, определение адреса метки может привести к изменению длины ссылающегося на нее кода, поэтому на таких архитектурах оказывается целесообразным трех- и более проходное ассемблирование. При однопроходном ассемблировании, мы запоминаем все точки, из которых происходят ссылки вперед, и, определив адрес символа, возвращаемся к этим точкам и записываем в них адрес. При однопроходном ассемблировании целесообразно хранить код, в котором еще не все метки расставлены, в оперативной памяти, поэтому в старых компьютерах двухпроходные ассемблеры были широко распространены. Впрочем, современные многопроходные ассемблеры также хранят промежуточные представления программы в памяти, поэтому количество проходов в конкретной реализации ассемблера представляет разве что теоретический интерес. |
Прикладные протоколы
Протоколы прикладного уровня служат для передачи информации конкретным клиентским приложениям, запущенным на сетевом компьютере. В IP-сетях протоколы прикладного уровня опираются на стандарт TCP и выполняют ряд специализированных функций, предоставляя пользовательским программам данные строго определенного назначения. Ниже мы кратко рассмотрим несколько прикладных протоколов стека TCP/IP.
Протокол FTP
Как следует из названия, протокол FTP (File Transfer Protocol) предназначен для передачи файлов через Интернет. Именно на базе этого протокола реализованы процедуры загрузки и выгрузки файлов на удаленных узлах Всемирной Сети. FTP позволяет переносить с машины па машину не только файлы, но и целые папки, включающие поддиректории на любую глубину вложений. Осуществляется это путем обращения к системе команд FTP, описывающих ряд встроенных функций данного протокола.
Протокол HTTP
Протокол HTTP (Hyper Text Transfer Protocol) обеспечивает передачу с удаленных серверов на локальный компьютер документов, содержащих код разметки гипертекста, написанный на языке HTML или XML, то есть веб-страниц. Данный прикладной протокол ориентирован прежде всего на предоставление информации программам просмотра веб-страниц, веб-браузерам, наиболее известными из которых являются такие приложения, как Microsoft Internet Explorer и Netscape Communicator.
Именно с использованием протокола HTTP организуется отправка запросов удаленным http-серверам сети Интернет и обработка их откликов; помимо
этого HTTP позволяет использовать для вызова ресурсов Всемирной сети адреса стандарта доменной системы имен (DNS, Domain Name System), то есть обозначения, называемые URL (Uniform Resource Locator) вида http:/ /www.domain.zone/page.htm (.html).
Протокол IP
Протокол IP (Internet Protocol) используется как в глобальных распределенных системах, например в сети Интернет, так и в локальных сетях. Впервые протокол IP применялся еще в сети ArpaNet, являвшейся предтечей современного Интернета, и с тех пор он уверенно удерживает позиции в качестве одного из наиболее распространенных и популярных протоколов межсетевого уровня.
Поскольку межсетевой протокол IP является универсальным стандартом, он нередко применяется в так называемых составных сетях, то есть сетях, использующих различные технологии передачи данных и соединяемых между собой посредством шлюзов. Этот же протокол «отвечает» за адресацию при передаче информации в сети. Как осуществляется эта адресация?
Каждый человек, живущий на Земле, имеет адрес, по которому его в случае необходимости можно разыскать. Думаю, ни у кого не вызовет удивления то, что каждая работающая в Интернете или локальной сети машина также имеет свой уникальный адрес. Адреса в компьютерных сетях разительно отличаются от привычных нам почтовых. Боюсь, совершенно бесполезно писать на отправляемом вами в Сеть пакете информации нечто вроде «Компьютеру Intel Pentium III 1300 Mhz, эсквайру, Пэнии-Лэйн 114, Ливерпуль, Англия». Увидев такую надпись, ваша персоналка в лучшем случае фундаментально зависнет. Но если вы укажете компьютеру в качестве адреса нечто вроде 195.85.102.14, машина вас прекрасно поймет.
Именно стандарт IP подразумевает подобную запись адресов подключенных к сети компьютеров. Такая запись носит название IP-адрес.
Из приведенного примера видно, что IP-адрес состоит из четырех десятичных идентификаторов, или октетов, по одному байту каждый, разделенных точкой. Левый октет указывает тип локальной интрасети (под термином «интрасеть» (intranet) здесь понимается частная корпоративная или домашняя локальная сеть, имеющая подключение к Интернету), в которой находится искомый компьютер. В рамках данного стандарта различается несколько подвидов интрасетей, определяемых значением первого октета.
Это значение характеризует максимально возможное количество подсетей и узлов, которые может включать такая сеть. В табл. 2.1 приведено соответствие классов сетей значению первого октета IP-адреса.
Таблица 2.1. Соответствие классов сетей значению первого октета IP-адреса
| Класс сети | Диапазон значений первого октета | Возможное количество подсетей |
Возможное количество узлов |
| A | 1-126 | 126 | 16777214 |
| B | 128-191 | 16382 | 65534 |
| C | 192-223 | 2097150 | 254 |
| D | 224-239 | - | 2-28 |
| E | 240-247 | - | 2-27 |
Таблица 2.2. Значение выделенных IP-адресов
| IP-адрес | Значение |
| 0.0.0.0 | Данный компьютер |
| Номер сети. 0.0.0 | Данная IP-сеть |
| 0.0.0.номер хоста | Конкретный компьютер в данной локальной IP-сети |
| 1.1.1.1 | Все компьютеры в данной локальной IP-сети |
| Номер сети. 1.1.1 | Все компьютеры в указанной IP-сети |
Хостом принято называть любой подключенный к Интернету компьютер независимо от его назначения.
Как уже упоминалось ранее, небольшие локальные сети могут соединяться между собой, образуя более сложные и разветвленные структуры. Например, локальная сеть предприятия может состоять из сети административного корпуса и сети производственного отдела, сеть административного корпуса, в свою очередь, может включать в себя сеть бухгалтерии, планово-экономического отдела и отдела маркетинга.
В приведенном выше примере сеть более низкого уровня является подсетью системы более высокого уровня, то есть локальная сеть бухгалтерии — подсеть для сети административного корпуса, а та, в свою очередь, — подсеть для сети всего предприятия в целом.
Однако вернемся к изучению структуры IP-адреса. Последний (правый) идентификатор IP-адреса обозначает номер компьютера в данной локальной сети. Все, что расположено между правым и левым октетами в такой записи, — номера подсетей более низкого уровня. Непонятно? Давайте разберем на примере. Положим, мы имеем некий адрес в Интернете, на который хотим отправить пакет с набором свеженьких анекдотов. В качестве примера возьмем тот же IP-адрес— 195.85.102.14. Итак, мы отправляем пакет в 195-ю подсеть сети Интернет, которая, как видно из значения первого октета, относится к классу С. Допустим, 195-я сеть включает в себя еще 902 подсети, но наш пакет высылается в 85-ю. Она содержит 250 подсетей
более низкого порядка, но нам нужна 102-я. Ну и, наконец, к 102-й сети подключено 40 компьютеров. Исходя из рассматриваемого нами адреса, подборку анекдотов получит машина, имеющая в этой сетевой системе номер 14. Из всего сказанного выше становится очевидно, что IP-адрес каждого компьютера, работающего как в локальной сети, так и в глобальных вычислительных системах, должен быть уникален.
Централизованным распределением IP-адресов в локальных сетях занимается государственная организация — Стенфордский международный научно-исследовательский институт (Stanford Research Institute, SRI International), расположенный в самом сердце Силиконовой долины — городе Мэнло-Парк, штат Калифорния, США. Услуга по присвоению новой локальной сети IP-адресов бесплатная, и занимает она приблизительно неделю. Связаться с данной организацией можно по адресу SRI International, Room EJ210, 333 Ravenswood Avenue, Menlo Park, California 94025, USA, no телефону в США 1-800-235-3155 или по адресу электронной почты, который можно найти на сайте http://www.sri.com.
Однако большинство администраторов небольших локальных сетей, насчитывающих 5—10 компьютеров, назначают IP-адреса подключенным к сети машинам самостоятельно, исходя из описанных выше правил адресации в IP-сетях. Тацой подход вполне имеет право на жизнь, но вместе с тем произвольное назначение IP-адресов может стать проблемой, если в будущем такая сеть будет соединена с другими локальными сетями или в ней будет организовано прямое подключение к Интернету. В данном случае случайное совпадение нескольких IP-адресов может привести к весьма неприятным последствиям, например к ошибкам в маршрутизации передаваемых по сети данных или отказу в работе всей сети в целом.
Небольшие локальные сети, насчитывающие ограниченное количество компьютеров, должны запрашивать для регистрации адреса класса С. При этом каждой из таких сетей назначаются только два первых октета IP-адреса, например 197.112.Х.Х, на практике это означает, что администратор данной сети может создавать подсети и назначать номера узлов в рамках каждой из них произвольно, исходя из собственных потребностей.
Большие локальные сети, использующие в качестве базового межсетевой протокол IP, нередко применяют чрезвычайно удобный способ структуризации всей сетевой системы путем разделения общей IP-сети на подсети. Например, если вся сеть предприятия состоит из ряда объединенных вместе локальных сетей Ethernet, то в ней может быть выделено несколько структурных составляющих, то есть подсетей, отличающихся значением третьего октета IP-адреса. Как правило, в качестве каждой из подсетей используется физическая сеть какого-либо отдела фирмы, скажем, сеть Ethernet, объединяющая все компьютеры бухгалтерии. Такой подход, во-первых, позволяет
излишне не расходовать IP-адреса, а во-вторых, предоставляет определенные удобства с точки зрения администрирования: например, администратор может открыть доступ к Интернету только для одной из вверенных ему подсетей или на время отключить одну из подсетей от локальной сети предприятия.
Кроме того, в случае если сетевой администратор решит, что третий октет IP-адреса описывает номер подсети, а четвертый — номер узла в ней, то такая информация записывается в локальных таблицах маршрутизации сети вашего предприятия и не видна извне. Другими словами, данный подход обеспечивает большую безопасность.
Для того чтобы программное обеспечение могло автоматически выделять номера конкретных компьютеров из используемых в данной сетевой системе IP-адресов, применяются так называемые маски подсети. Принцип, по которому осуществляется распознавание номеров узлов в составе IP-адреса, достаточно прост: биты маски подсети, обозначающие номер самой IP-сети, должны быть равны единице, а биты, определяющие номер узла, — нулю. Именно поэтому в большинстве локальных IP-сетей класса С в качестве маски подсети принято значение 255.255.255.0: при такой конфигурации в состав общей сети может быть включено до 256 подсетей, в каждой из которых работает до 254 компьютеров. В ряде случаев это значение может изменяться, например, если возникла необходимость использовать в составе сети количество подсетей большее, чем 256, можно использовать маску подсети формата 255.255.255.195. В этой конфигурации сеть может включать до 1024 подсетей, максимальное число компьютеров в каждой из которых не должно превышать 60.
В локальных сетях, работающих под управлением межсетевого протокола IP, помимо обозначения IP-адресов входящих в сеть узлов принято также символьное обозначение компьютеров: например, компьютер с адресом 192.112.85.7 может иметь сетевое имя Localhost. Таблица соответствий IP-адресов символьным именам узлов содержится в специальном файле hosts, хранящемся в одной из системных папок; в частности, в операционной системе Microsoft Windows XP этот файл можно отыскать в папке flKCK:\Windows\system32\drivers\etc\. Синтаксис записи таблицы сопоставлений имен узлов локальной сети IP-адресам достаточно прост: каждый элемент таблицы должен быть расположен в новой строке, IP-адрес располагается в первом столбце, а за ним следует имя компьютера, при этом IP-адрес и имя должны быть разделены как минимум одним пробелом.
Каждая из строк таблицы может включать произвольный комментарий, обозначаемый символом #. Пример файла hosts приведен ниже:
192.112.85.7 localhost # этот компьютер
192.112.85.1 server # сервер сети
192.112.85.2 director # компьютер приемной директора
192.112.85.5 admin # компьютер системного администратора
Как правило, файл hosts создается для какой-либо конкретной локальной сети, и его копия хранится на каждом из подключенных к ней компьютеров. В случае, если один из узлов сети имеет несколько IP-адресов, то в таблице соответствий обычно указывается лишь один из них, вне зависимости от того, какой из адресов реально используется. При получении из сети IP-пакета, предназначенного для данного компьютера, протокол IP сверится с таблицей маршрутизации и на основе анализа заголовка IP-пакета автоматически опознает любой из IP-адресов, назначенных данному узлу.
Помимо отдельных узлов сети собственные символьные имена могут иметь также входящие в локальную сеть подсети. Таблица соответствий IP-адресов именам подсетей содержится в файле networks, хранящемся в той же папке, что и файл hosts. Синтаксис записи данной таблицы сопоставлений несколько отличается от предыдущего, и в общем виде выглядит следующим образом: <сетевяе имя> <номер сети> [псевдонимы...] [#<конментарий>]
где сетевое имя — имя, назначенное каждой подсети, номер сети — часть IP-адреса подсети (за исключением номеров более мелких подсетей, входящих в данную подсеть, и номеров узлов), псевдонимы — необязательный параметр, указывающий на возможные синонимы имен подсетей: они используется в случае, если какая-либо подсеть имеет несколько различных символьных имен; и, наконец, комментарий — произвольный комментарий, поясняющий смысл каждой записи. Пример файла networks приведен ниже:
loopback 127
marketing 192.112.85 # отдел маркетинга
buhgalteria 192.112.81 # бухгалтерия
workshop 192.112.80 # сеть производственного цеха
workgroup 192.112.10 localnetwork # основная рабочая группа
Обратите внимание на то обстоятельство, что адреса, начинающиеся на 127, являются зарезервированными для протокола IP, а подсеть с адресом 192.112.10 в нашем примере имеет два символьных имени, используемых совместно.
Файлы hosts и networks не оказывают непосредственного влияния на принципиальный механизм работы протокола IP и используются в основном прикладными программами, однако они существенно облегчают настройку и администрирование локальной сети.
Протокол IPX
Протокол IPX (Internet Packet Exchange) является межсетевым протоколом, используемым в локальных сетях, узлы которых работают под управлением операционных систем семейства Nowell Netware. Данный протокол обеспечивает передачу дейтаграмм в таких сетях без организации логического соединения — постоянного двустороннего обмена данными между двумя узлами сети, которое организуется протоколом транспортного уровня. Разработанный на основе технологий Nowell, этот некогда популярный протокол в силу несовместимости с чрезвычайно распространенным стеком протоколов TCP/IP в настоящее время медленно, но верно утрачивает свои позиции.
Как и межсетевой протокол IP, IPX способен поддерживать широковещательную передачу данных посредством дейтаграмм длиной до 576 байт, 30 из которых занимает заголовок пакета. В сетях IPX используются составные адреса узлов, состоящих из номера сети, адреса узла и адреса прикладной программы, для которой предназначен передаваемый пакет информации, который также носит наименование гнезда или сокета. Для обеспечения обмена данными между несколькими сетевыми приложениями в многозадачной среде на узле, работающем под управлением протокола IPX, должно быть одновременно открыто несколько сокетов.
Поскольку в процессе трансляции данных протокол IPX не запрашивает подтверждения получения дейтаграмм, доставка данных в таких сетях не гарантируется, и потому функции контроля над передачей информации возлагаются на сетевое программное обеспечение. Фактически IPX обеспечивает только инкапсуляцию транслируемых по сети потоков данных в дейтаграммы, их маршрутизацию и передачу пакетов протоколам более высокого уровня.
Протоколам канального уровня IPX передает пакеты данных, имеющие следующую логическую структуру:
контрольная сумма, предназначенная для определения целостности передаваемого пакета (2 байта);
указание на длину пакета (2 байта);
данные управления транспортом (1 байт);
адрес сети назначения (4 байта);
адрес узла назначения (6 байт);
номер сокета назначения (2 байта);
адрес сети-отправителя (4 байта);
адрес узла-отправителя (6 байт);
номер сокета-отправителя (2 байта);
передаваемая информация (0-546 байт).
Протоколы канального уровня размещают этот пакет внутри кадра сети и передают его в распределенную вычислительную систему.
Протокол SPX
В точности так же, как протокол TCP для IP-сетей, для сетей, построенных на базе межсетевого протокола IPX, транспортным протоколом служит специальный протокол SPX (Sequenced Pocket eXchange). В таких локальных сетях протокол SPX выполняет следующий набор функций:
инициализация соединения;
организация виртуального канала связи (логического соединения);
проверка состояния канала;
контроль передачи данных;
разрыв соединения.
Поскольку транспортный протокол SPX и межсетевой протокол IPX тесно связаны между собой, их нередко объединяют в общее понятие — семейство протоколов IPX/SPX. Поддержка данного семейства протоколов реализована не только в операционных системах семейства Nowell Netware, но и в ОС Microsoft Windows 9x/Me/NT/2000/XP, Unix/Linux и OS/2.
Протокол TCP
Протокол IP позволяет только транслировать данные. Для того чтобы управлять этим процессом, служит протокол TCP (Transmission Control Protocol), опирающийся на возможности протокола IP. Как же контролируется передача информации?
Положим, вы хотите переслать по почте вашему другу толстый журнал, не потратив при этом денег на отправку бандероли. Как решить эту проблему, если почта отказывается принимать письма, содержащие больше нескольких бумажных листов? Выход простой: разделить журнал на страницы и отправлять их отдельными письмами. По номерам страниц ваш друг сможет собрать журнал целиком. Приблизительно таким же способом работает протокол TCP. Он дробит информацию на несколько частей, присваивает каждой части номер, по которому данные впоследствии можно будет соединить воедино, добавляет к ней «служебную» информацию и укладывает все это в отдельный «IP-конверт». Далее этот «конверт» отправляется по сети — ведь протокол межсетевого уровня умеет обрабатывать подобную информацию. Поскольку в такой схеме протоколы TCP и IP тесно связаны, их часто объединяют в одно понятие: TCP/IP. Размер передаваемых в Интернете TCP/IP-пакетов составляет, как правило, от 1 до 1500 байт, что связано с техническими характеристиками сети.
Наверняка, пользуясь услугами обычной почтовой связи, вы сталкивались с тем, что обычные письма, посылки и иные почтовые отправления теряются и приходят совсем не туда, куда нужно. Те же проблемы характерны и для локальных сетей. На почте такие неприятные ситуации решают руководители почтовых отделений, а в сетевых системах этим занимается протокол TCP. Если какой-либо пакет данных не был доставлен получателю вовремя, TCP повторяет пересылку до тех пор, пока информация не будет принята корректно и в полном объеме.
В действительности данные, передаваемые по электронным сетям, не только теряются, но зачастую искажаются из-за помех на линиях связи. Встроенные в TCP алгоритмы контроля корректности передачи данных решают и эту проблему. Одним из самых известных механизмов контроля правильности пересылки информации является метод, согласно которому в заголовок каждого передаваемого пакета записывается некая контрольная сумма, вычисленная компьютером-отправителем.
Компьютер- получатель по аналогичной системе вычисляет контрольную сумму и сравнивает ее с числом, имеющимся в заголовке пакета. Если цифры не совпадают, TCP пытается повторить передачу.
Следует отметить также, что при отправке информационных пакетов протокол TCP требует от компьютера-получателя подтверждения приема информации. Это организуется путем создания временных задержек при приеме-передаче — тайм-аутов, или ожиданий. Тем временем отправитель продолжает пересылать данные. Образуется некий объем уже переданных, но еще не подтвержденных данных. Иными словами, TCP организует двунаправленный обмен информацией, что обеспечивает более высокую скорость ее трансляции.
При соединении двух компьютеров их модули TCP следят за состоянием связи. При этом само соединение, посредством которого осуществляется обмен данными, носит название виртуального или логического канала.
Фактически протокол TCP является неотъемлемой частью стека протоколов TCP/IP, и именно с его помощью реализуются все функции контроля над передачей информации по сети, а также задачи ее распределения между клиентскими приложениями.
Протокол TELNET
Протокол TELNET предназначен для организации терминального доступа к удаленному узлу посредством обмена командами в символьном формате ASCII. Как правило, для работы с сервером по протоколу TELNET на стороне клиента должна быть установлена специальная программа, называемая telnet-клиентом, которая, установив связь с удаленным узлом, открывает в своем окне системную консоль операционной оболочки сервера. После этого вы можете управлять серверным компьютером в режиме терминала, как своим собственным (естественно, в очерченных администратором рамках). Например, вы получите возможность изменять, удалять, создавать, редактировать файлы и папки, а также запускать на исполнение программы на диске серверной машины, сможете просматривать содержимое папок других пользователей. Какую бы операционную систему вы ни использовали, протокол Telnet позволит вам общаться с удаленной машиной «на равных». Например, вы без труда сможете открыть сеанс UNIX на компьютере, работающем под управлением MS Windows.
Протокол UDP
Прикладной протокол передачи данных UDP (User Datagram Protocol) используется на медленных линиях для трансляции информации как дейтаграмм.
Дейтаграмма содержит полный комплекс данных, необходимых для ее отсылки и получения. При передаче дейтаграмм компьютеры не занимаются обеспечением стабильности связи, поэтому следует принимать особые меры для обеспечения надежности.
Схема обработки информации протоколом UDP, в принципе, такая же, как и в случае с TCP, но с одним отличием: UDP всегда дробит информацию по одному и тому же алгоритму, строго определенным образом. Для осуществления связи с использованием протокола UDP применяется система отклика: получив UDP-пакет, компьютер отсылает отправителю заранее обусловленный сигнал. Если отправитель ожидает сигнал слишком долго, он просто повторяет передачу.
На первый взгляд может показаться, что протокол UDP состоит сплошь из одних недостатков, однако есть в нем и одно существенное достоинство: прикладные интернет-программы работают с UDP в два раза быстрее, чем с его более высокотехнологичным собратом TCP.
Протоколы канального уровня
Протоколы, обеспечивающие взаимодействие компьютера с сетью на самом низком, аппаратном уровне, во многом определяют топологию локальной сети, а также ее внутреннюю архитектуру. В настоящее время на практике достаточно часто применяется несколько различных стандартов построения локальных сетей, наиболее распространенными среди которых являются технологии Ethernet, Token Ring, Fiber Distributed Data Interface (FDDI) и ArcNet.
На сегодняшний день локальные сети, построенные на основе стандарта Ethernet, являются наиболее популярными как в нашей стране, так и во всем мире. На долю сетей Ethernet приходится почти девяносто процентов всех малых и домашних локальных сетей, что не удивительно, поскольку именно эта технология позволяет строить простые и удобные в эксплуатации и настройке локальные сети с минимумом затрат. Именно поэтому в качестве основного рассматриваемого нами стандарта будет принята именно технология Ethernet. Протоколы канального уровня поддержки Ethernet, как правило, встроены в оборудование, обеспечивающее подключение компьютера к локальной сети на физическом уровне. Стандарт Ethernet является широковещательным, то есть каждый подключенный к сети компьютер принимает всю следующую через его сетевой сегмент информацию — как предназначенную именно для этого компьютера, так и данные, направляемые на другую машину. Во всех сетях Ethernet применяется один и тот же алгоритм разделения среды передачи информации — множественный доступ с контролем несущей и обнаружением конфликтов (Carrier Sense Multiple Access with Collision Detection, CSMA/CD).
В рамках технологии Ethernet сегодня различается несколько стандартов организации сетевых коммуникаций, определяющих пропускную способность канала связи и максимально допустимую длину одного сегмента сети, то есть расстояние между двумя подключенными к сети устройствами. Об этих стандартах мы побеседуем в следующей главе, посвященной изучению сетевого оборудования, пока же необходимо отметить, что в рамках стандарта Ethernet применяется, как правило, одна из двух различных топологий: конфигурация сети с общей шиной или звездообразная архитектура.
Протоколы межсетевого уровня
Протоколы уровня межсетевого взаимодействия, как уже упоминалось ранее, предназначены для определения маршрутов следования информации в локальной сети, приема и передачи дейтаграмм, а также для трансляции принятых данных протоколам более высокого уровня, если эти данные предназначены для обработки на локальном компьютере. К протоколам межсетевого уровня принято относить протоколы маршрутизации, такие как RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол контроля и управления передачей данных ICMP (Internet Control Message Protocol). Но вместе с тем одним из самых известных протоколов межсетевого уровня является протокол IP.
Протоколы NetBIOS/NetBEUI
Разработанный компанией IBM транспортный протокол NetBIOS (Network Basic Input/Output System) является базовым протоколом для локальных
сетей, работающих под управлением операционных систем семейств Nowell Netware и OS/2, однако его поддержка реализована также и в ОС Microsoft Windows, и в некоторых реализациях Unix-совместимых операционных систем. Фактически можно сказать, что данный протокол работает сразу на нескольких логических уровнях стека протоколов: на транспортном уровне он организует интерфейс между сетевыми приложениями в качестве надстройки над протоколами IPX/SPX, на межсетевом — управляет маршрутизацией дейтаграмм, на канальном уровне — организует обмен сообщениями между различными узлами сети.
В отличие от других протоколов, NetBIOS осуществляет адресацию в локальных сетях на основе уникальных имен узлов и практически не требует настройки, благодаря чему остается весьма привлекательным для системных администраторов, управляющих сетями с небольшим числом компьютеров. В качестве имен хостов протоколом NetBIOS используются значащие последовательности длиной в 16 байт, то есть каждый узел сети имеет собственное уникальное имя (permanent name), которое образуется из сетевого адреса машины с добавлением десяти служебных байтов. Кроме этого, каждый компьютер в сетях NetBIOS имеет произвольное символьное имя, равно как произвольные имена могут иметь логические*рабочие группы, объединяющие несколько работающих совместно узлов — такие имена могут назначаться и удаляться по желанию системного администратора. Имена узлов служат для идентификации компьютера в сети, имена рабочих групп могут служить, в частности, для отправки данных нескольким компьютерам группы или для обращения к целому ряду сетевых узлов одновременно.
При каждом подключении к распределенной вычислительной системе протокол NetBIOS осуществляет опрос локальной сети для проверки уникальности имени узла; поскольку несколько узлов сети могут иметь идентичные групповые имена, определение уникальности группового имени не производится.
Специально для локальных сетей, работающих на базе стандарта NetBIOS, корпорацией IBM был разработан расширенный интерфейс для этого протокола, который получил название NetBEUI (NetBIOS Extended User Interface). Этот протокол рассчитан на поддержку небольших локальных сетей, включающих не более 150-200 машин, и по причине того, что данный протокол может использоваться только в отдельных сегментах локальных сетей (пакеты NetBEUI не могут транслироваться через мосты — устройства, соединяющие несколько локальных сетей, нередко использующих различную среду передачи данных или различную топологию), этот стандарт считается устаревшим и более не поддерживается операционной системой Microsoft Windows XP, хотя его поддержка имеется в ОС семейства Windows 9х/МЕ/2000.
Протоколы РОРЗ и SMTP
Прикладные протоколы, используемые при работе с электронной почтой, называются SMTP (Simple Mail Transfer Protocol) и РОРЗ (Post Office Protocol), первый «отвечает» за отправку исходящей корреспонденции, второй — за доставку входящей.
В функции этих протоколов входит организация доставки сообщений e-mail и передача их почтовому клиенту. Помимо этого, протокол SMTP позволяет отправлять несколько сообщений в адрес одного получателя, организовывать промежуточное хранение сообщений, копировать одно сообщение для отправки нескольким адресатам. И РОРЗ, и SMTP обладают встроенными механизмами распознавания адресов электронной почты, а также специальными модулями повышения надежности доставки сообщений.
Сетевые протоколы
Стеки протоколов
Протоколы канального уровня
Протоколы межсетевого уровня
Транспортные протоколы
Прикладные протоколы
Как уже упоминалось ранее, в локальных сетях могут совместно работать компьютеры разных производителей, оснащенные различным набором устройств и обладающие несхожими техническими характеристиками. На практике это означает, что для обеспечения нормального взаимодействия этих компьютеров необходим некий единый унифицированный стандарт, строго определяющий алгоритм передачи данных в распределенной вычислительной системе. В современных локальных сетях, или, как их принято называть в англоязычных странах, LAN (Local Area Network), роль такого стандарта выполняют сетевые протоколы.
Итак, сетевым протоколом, или протоколом передачи данных, называется согласованный и утвержденный стандарт, содержащий описание правил приема и передачи между несколькими компьютерами команд, файлов, иных данных, и служащий для синхронизации работы вычислительных машин в сети.
Прежде всего следует понимать, что в локальных сетях передача информации осуществляется не только между компьютерами как физическими устройствами, но и между приложениями, обеспечивающими коммуникации на программном уровне. Причем под такими приложениями можно понимать как компоненты операционной системы, организующие взаимодействие с различными устройствами компьютера, так и клиентские приложения, обеспечивающие интерфейс с пользователем. Таким образом, мы постепенно приходим к пониманию многоуровневой структуры сетевых коммуникаций — как минимум, с одной стороны мы имеем дело с аппаратной конфигурацией сети, с другой стороны — с программной.
Вместе с тем передача информации между несколькими сетевыми компьютерами — не такая уж простая задача, как это может показаться на первый взгляд. Для того чтобы понять это, достаточно представить себе тот круг проблем, который может возникнуть в процессе приема или трансляции каких-либо данных. В числе таких «неприятностей» можно перечислить аппаратный сбой либо выход из строя одного из обеспечивающих связь устройств, например, сетевой карты или концентратора, сбой прикладного или системного программного обеспечения, возникновение ошибки в самих передаваемых данных, потерю части транслируемой информации или ее искажение.
Отсюда следует, что в локальной сети необходимо обеспечить жесткий контроль для отслеживания всех этих ошибок, и более того, организовать четкую работу как аппаратных, так и программных компонентов сети. Возложить все эти задачи на один-единственный протокол практически невозможно. Как быть?
Выход нашелся в разделении протоколов на ряд концептуальных уровней, каждый из которых обеспечивает интерфейс между различными модулями программного обеспечения, установленного на работающих в сети компьютерах. Таким образом, механизм передачи какого-либо пакета информации через сеть от клиентской программы, работающей на о/щом компьютере, клиентской программе, работающей на другом компьютере, можно условно представить в виде последовательной пересылки этого пакета сверху вниз от некоего протокола верхнего уровня, обеспечивающего взаимодействие с пользовательским приложением, протоколу нижнего уровня, организующему интерфейс с сетью, его трансляции на компьютер-получатель и обратной передачи протоколу верхнего уровня уже на удаленной машине (рис. 2.1).
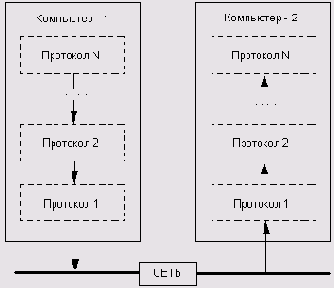
Рис. 2.1. Концептуальная модель многоуровневой системы протоколов
Согласно такой схеме, каждый из уровней подобной системы обеспечивает собственный набор функций при передаче информации по локальной сети.
Например, можно предположить, что протокол верхнего уровня, осуществляющий непосредственное взаимодействие с клиентскими программами, транслирует данные протоколу более низкого уровня, «отвечающему» за работу с аппаратными устройствами сети, преобразовывая их в «понятную» для него форму. Тот, в свою очередь, передает их протоколу, осуществляющему непосредственно пересылку информации на другой компьютер. На удаленном компьютере прием данных осуществляет аналогичный протокол «нижнего» уровня и контролирует корректность принятых данных, то есть определяет, следует ли транслировать их протоколу, расположенному выше в иерархической структуре, либо запросить повторную передачу. В этом случае взаимодействие осуществляется только между протоколами нижнего уровня, верхние уровни иерархии в данном процессе не задействованы.
В случае если информация была передана без искажений, она транслируется вверх через соседние уровни протоколов до тех пор, пока не достигнет программы-получателя. При этом каждый из уровней не только контролирует правильность трансляции данных на основе анализа содержимого пакета информации, но и определяет дальнейшие действия исходя из сведений о его назначении. Например, один из уровней «отвечает» за выбор устройства, с которого осуществляется получение и через которое передаются данные в сеть, другой «решает», передавать ли информацию дальше по сети, или она предназначена именно этому компьютеру, третий «выбирает» программу, которой адресована принятая информация. Подобный иерархический подход позволяет не только разделить функции между различными модулями сетевого программного обеспечения, что значительно облегчает контроль работы всей системы в целом, но и дает возможность производить коррекцию ошибок на том уровне иерархии, на котором они возникли. Каждую из подобных иерархических систем, включающих определенный набор протоколов различного уровня, принято называть стеком протоколов.
Вполне очевидно, что между теорией и практикой, то есть между концептуальной моделью стека протоколов и его практической реализацией существует значительная разница. На практике принято несколько различных вариантов дробления стека протоколов на функциональные уровни, каждый из которых выполняет свой круг задач. Мы остановимся на одном из этих вариантов, который представляется наиболее универсальным. Данная схема включает четыре функциональных уровня, и так же, как и предыдущая диаграмма, описывает не конкретный механизм работы какого-либо стека протоколов, а общую модель, которая поможет лучше понять принцип действия подобных систем (рис. 2.2).
Самый верхний в иерархической системе, прикладной уровень стека протоколов обеспечивает интерфейс с программным обеспечением, организующим
работу пользователя в сети. При запуске любой программы, для функционирования которой требуется диалог с сетью, эта программа вызывает соответствующий протокол прикладного уровня.
Данный протокол передает программе информацию из сети в доступном для обработки формате, то есть в виде системных сообщений либо в виде потока байтов. В точности таким же образом пользовательские приложения могут получать потоки данных и управляющие сообщения — как от самой операционной системы, так и от других запущенных на компьютере программ. То есть, обобщая, можно сказать, что протокол прикладного уровня выступает в роли своего рода посредника между сетью и программным обеспечением, преобразуя транслируемую через сеть информацию в «понятную» программе-получателю форму.
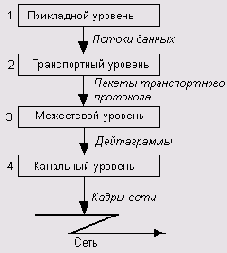
Рис. 2.2. Модель реализации стека протоколов
Основная задача протоколов транспортного уровня заключается в осуществлении контроля правильности передачи данных, а также в обеспечении взаимодействия между различными сетевыми приложениями. В частности, получая входящий поток данных, протокол транспортного уровня дробит его на отдельные фрагменты, называемые пакетами, записывает в каждый пакет некоторую дополнительную информацию, например идентификатор программы, для которой предназначены передаваемые данные, и контрольную сумму, необходимую для проверки целостности пакета, и направляет их на смежный уровень для дальнейшей обработки. Помимо этого протоколы транспортного уровня осуществляют управление передачей информации — например, могут запросить у получателя подтверждение доставки пакета и повторно выслать утерянные фрагменты транслируемой последовательности данных. Некоторое недоумение может вызвать то обстоятельство, что протоколы транспортного уровня так же, как и протоколы прикладного уровня, взаимодействуют с сетевыми программами и координируют передачу данных между ними. Эту ситуацию можно прояснить на следующем примере: предположим, на подключенном к сети компьютере запущен почтовый клиент, эксплуатирующий два различных протокола прикладного уровня — РОРЗ ( Post Office Protocol) и SMTP (Simple Mail Transfer Protocol) — и программа загрузки файлов на удаленный сервер — FTP-клиент, работающий с протоколом прикладного уровня FTP (File Transfer Protocol).
Все эти протоколы прикладного уровня опираются на один и тот же протокол транспортного уровня — TCP/IP (Transmission Control Protocol/Internet Protocol), который, получая поток данных от вышеуказанных программ, преобразует их в пакеты данных, где присутствует указание на конечное приложение, использующее эту информацию. Из рассмотренного нами примера следует, что данные, приходящие из сети, могут иметь различное назначение, и, соответственно, они обрабатываются различными программами, либо различными модулями одного и того же приложения. Во избежание путаницы при приеме и обработке информации каждая взаимодействующая с сетью программа имеет собственный идентификатор, который позволяет транспортному протоколу направлять данные именно тому приложению, для которого они предназначены. Такие идентификаторы носят название программных портов. В частности, протокол прикладного уровня SMTP, предназначенный для отправки сообщений электронной почты, работает обычно с портом 25, протокол входящей почты РОРЗ — с портом 110, протокол Telnet — с портом 23. Задача перенаправления потоков данных между программными портами лежит па транспортных протоколах.
На межсетевом уровне реализуется взаимодействие конкретных компьютеров распределенной вычислительной системы, другими словами, осуществляется процесс определения маршрута движения информации внутри локальной сети и выполняется отправка этой информации конкретному адресату. Данный процесс принято называть маршрутизацией. Получая пакет данных от протокола транспортного уровня вместе с запросом на его передачу и указанием получателя, протокол межсетевого уровня выясняет, на какой компьютер следует передать информацию, находится ли этот компьютер в пределах данного сегмента локальной сети или на пути к нему расположен шлюз, после чего трансформирует пакет в дейтаграмму — специальный фрагмент информации, передаваемый через сеть независимо от других аналогичных фрагментов, без образования виртуального канала (специально сконфигурированной среды для двустороннего обмена данными между несколькими устройствами) и подтверждения приема.
В заголовок дейтаграммы записывается адрес компьютера-получателя пересылаемых данных и сведения о маршруте следования дейтаграммы. После чего она передается на канальный уровень.
ПРИМЕЧАНИЕ
Шлюз — это программа, при помощи которой можно передавать информацию между двумя сетевыми системами, использующими различные протоколы обмена данными.
Получая дейтаграмму, протокол межсетевого уровня определяет правильность ее приема, после чего выясняет, адресована ли она локальному компьютеру, или же ее следует направить по сети дальше. В случае, если дальнейшей пересылки не требуется, протокол межсетевого уровня удаляет заголовок дейтаграммы, вычисляет, какой из транспортных протоколов данного компьютера будет обрабатывать полученную информацию, трансформирует ее в соответствующий пакет и передает на транспортный уровень. Проиллюстрировать этот на первый взгляд сложный механизм можно простым примером. Предположим, на пеком компьютере одновременно используется два различных транспортных протокола: TCP/IP — для соединения с Интернетом и NetBEUI (NetBIOS Extended User Interface) для работы в локальной сети. В этом случае данные, обрабатываемые на транспортном уровне, будут для этих протоколов различны, однако на межсетевом уровне информация будет передаваться посредством дейтаграмм одного и того же формата.
Наконец, на канальном уровне осуществляется преобразование дейтаграмм в соответствующий сигнал, который через коммуникационное устройство транслируется по сети. В самом простом случае, когда компьютер напрямую подключен к локальной сети того или иного стандарта посредством сетевого адаптера, роль протокола канального уровня играет драйвер этого адаптера, непосредственно реализующий интерфейс с сетью. В более сложных ситуациях на канальном уровне могут работать сразу несколько специализированных протоколов, каждый из которых выполняет собственный набор функций.
Сквозные протоколы и шлюзы
Интернет — это единая глобальная структура, объединяющая на сегодня около 13 000 различных локальных сетей, не считая отдельных пользователей. Раньше все сети, входившие в состав Интернета, использовали сетевой протокол IP. Однако настал момент, когда пользователи локальных систем, не использующих IP, тоже попросились в лоно Интернета. Так появились шлюзы.
Поначалу через шлюзы транслировалась только электронная почта, но вскоре пользователям и этого стало мало. Теперь посредством шлюзов можно передавать любую информацию — и графику, и гипертекст, и музыку, и даже видео. Информация, пересылаемая через такие сети другим сетевым системам, транслируется с помощью сквозного протокола, обеспечивающего беспрепятственное прохождение IP-пакетов через не IP-сеть.
Сложные режимы адресации
| Сложные режимы адресации
реди промышленно выпускавшихся процессоров самым богатым набором экзотических режимов адресации обладает VAX. Кроме всех вышеперечисленных, предлагаются следующие. Косвенный с постинкрементом: регистр содержит адрес слова, которое является адресом операнда. После адресации регистр увеличивается на 4. Косвенный со смещением (не путать с косвенно-регистровым со смещением!): регистр со смещением адресует слово памяти, которое содержит адрес операнда — удобен для разыменования указателя без его загрузки в регистр. |
Транспортные протоколы
Как уже упоминалось ранее, протоколы транспортного уровня обеспечивают контроль над передачей данных между межсетевыми протоколами и приложениями уровня операционной системы. В настоящее время в локальных сетях наиболее распространено несколько разновидностей транспортных протоколов.
Вырожденные режимы адресации
| Вырожденные режимы адресации
К этой группе относятся режимы, в которых доступ к операнду не содержит адресации как таковой. Первым из таких режимов является операнд-регистр. Режим этот концептуально крайне прост и в дополнительных комментариях не нуждается. Второй режим — операнд-константа. В документаииях по многим процессорам этот режим называют литеральной (literal) и немедленной (immediate) адресацией. Казалось бы, трудно придумать более простой и жизненно необходимый режим. Однако полноценно реализовать такие операнды можно используя либо команды переменной длины, либо команды, которые длиннее слова (чаще всего это бывает у процессоров гарвардской архитектуры, например, уже упоминавшегося PIC). Литеральная адресация в системе команд SPARC Разработчики процессоров, которых не устраивает ни одно из названных условий, вынуждены проявлять фантазию. Так, у RISC-процессоров SPARC и команда, и слово имеют одинаковую длину— 32 бита. Адресное поле такой длины в команде невозможно — не остается места для кода операции. Выход, предложенный разработчиками архитектуры SPARC, при первом знакомстве производит странное впечатление, но, как говорят в таких случаях, "не критикуйте то, что работает". Трехадресные команды SPARC могут использовать в качестве операндов три регистра или два регистра и беззнаковую константу длиной 13 бит. Если константа, которую мы хотим использовать в операции, умещается в 13 бит, мы можем просто использовать эту возможность. На случай, если значение туда не помещается, предоставляется команда sethi const22, reg, которая имеет 22-разрядное поле и устанавливает старшие биты указанного регистра, равными этому полю, а младшие биты — равными нулю. Таким образом, если мы хотим поместить в регистр 32-разрядную константу value, мы должны делать это с помощью двух команд: sethi %hi (value), reg; or %gO, %lo (value), reg; (в соответствии с [docs.sun.com 806-3774-10], именно так реализована ассемблерная псевдокоманда set value, reg). С точки зрения занимаемой памяти, это ничуть не хуже, чем команда set value, reg, которая тоже должна была бы занимать 64 бита. Зато такое решение позволяет соблюсти принцип: одна команда — одно слово, который облегчает работу логике опережающей выборки команд. Впрочем, для 64-разрядного SPARC v9 столь элегантного решения найдено не было. Способ формирования произвольного 64-битового значения требует дополнительного регистра и целой программы (пример 2.1). В зависимости от значения константы этот код может подвергаться оптимизации. Легче всего, конечно, дело обстоит, если требуемое значение помещается в 13 бит. Пример 2.1. Формирование 64-разрядного значения на SPARC v9, цит. по [docs.sun.com 806-3774-10] ! reg — промежуточный регистр, rd — целевой. sethi %uhi(value), reg or reg, %ulo(value), reg sllx reg,32,reg ! сдвиг на 32 бита sethi %hi(value), rd or rd, reg, rd or rd, %lo(value), rd "Короткие литералы" разного рода нередко используются и в других процессорах, особенно имеющих большую разрядность. Действительно, большая часть реально используемых констант имеет небольшие значения, и выделение под каждую такую константу 32- или, тем более, 64-разрядного значения привело бы к ненужному увеличению кода. Короткие литералы VAX У процессоров семейства VAX есть режим адресации, позволяющий использовать битовое поле, которое в других режимах интерпретируется как номер регистра, в качестве 4-битового литерала. Вместе с двумя битами режима адресации этим способом можно задать 6-разрядный литерал, знаковый или беззнаковый в зависимости от контекста [Прохоров 1990]. Короткие литералы МСбЗОхО У процессоров семейства МС680хО литерал может иметь длину 1 или 2 байта. Кроме того, предоставляются команды ADDQ и SUBQ, которые позволяют добавить к указанному операнду или вычесть из него целое число в диапазоне от 1 до 8. |